
【エグゼクティブ・サマリー】
- MarvellがNVIDIAの支援を背景に、RAN(無線アクセスネットワーク)向け共通シリコンの市場投入を提唱。カスタムチップに依存してきた通信ベンダーのビジネスモデルを直撃する
- OCTEON 10 Fusionプロセッサ(5nmプロセス)とNVIDIA Aerial SDKの組み合わせが、vRAN(仮想化RAN)の導入コストと複雑性を大幅に圧縮する可能性がある
- O-RAN Allianceの標準(Split 7.2x)への準拠を武器に、マルチベンダー相互運用性を技術的に担保しつつ、通信インフラにおける半導体企業の影響力が構造的に拡大する局面に入った
既存テクノロジーの限界と課題
RANの世界は長らく、EricssonやNokia、Huaweiといった大手ベンダーによる垂直統合モデルが支配してきた。このモデルの核心にあるのが、各社が独自開発するカスタムASIC(特定用途集積回路)だ。
このアーキテクチャには構造的な問題が積み重なっている。
- 開発コストの非効率性: 5G NRの物理層(L1)処理は極めて計算負荷が高く、各社が個別にシリコンを設計・製造するコストは膨大。市場全体で見ると重複投資が著しい
- ベンダーロックイン: 独自チップで構成された基地局は、同一ベンダーの上位レイヤーソフトウェアとしか動作しない設計になっており、通信事業者の調達選択肢を著しく制限する
- スケールの非対称性: サーバー市場やクラウドインフラでは汎用CPU・GPUの進化がコモディティ化を加速してきたが、RANは「閉じた世界」として取り残されてきた
- vRANへの移行障壁: 基地局機能をソフトウェアとして汎用サーバー上で動かすvRANは概念としては確立しているが、レイテンシーや処理性能の要件が厳しいL1物理層の処理を汎用ハードウェアで賄うことが実用上のボトルネックになっていた
要するに、「無線通信専用にカスタマイズされたハードウェアでなければ動かない」という前提が、RANをオープン化・コモディティ化から隔絶させてきた。
ニュースの核心とアーキテクチャの優位性
MarvellがLight Readingのインタビューで訴えたメッセージの本質は「単一ベンダーのRANのために専用シリコンを設計するコストを、市場全体で分担せよ」という問題提起だ。
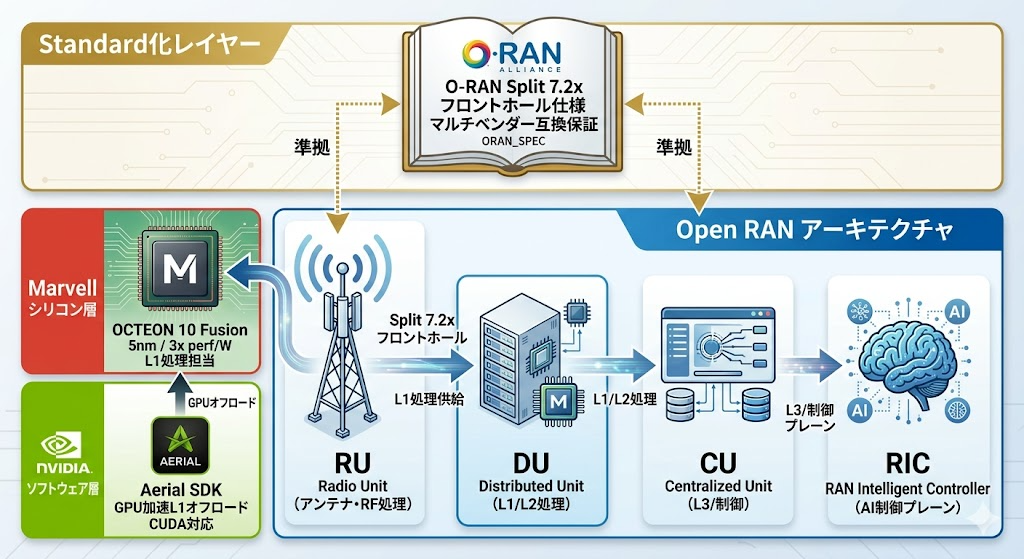
その実装の中心がOCTEON 10 Fusion 5Gベースバンドプロセッサである。
「Marvell OCTEON 10 Fusionは5nmプロセスを採用し、旧世代比でワットあたりの性能を最大3倍向上させている」 ——出典: Marvell公式製品ページ
3倍のワットパフォーマンスは単なるスペック競争ではない。基地局の電力コストは通信事業者のOPEXの中でも大きな比率を占めており、消費電力あたりの処理性能の向上は直接的にTCO(総所有コスト)の削減に直結する。
さらに重要なのが、NVIDIA Aerial SDKとの統合によるL1オフロードだ。
「NVIDIA Aerial SDKは、GPU加速による5G vRAN処理を可能にし、L1物理層のオフロードによってx86やArmサーバーの処理効率を大幅に向上させる」 ——出典: NVIDIA Aerial SDK
従来のvRANで最大の障害だったのが、L1(物理層)のリアルタイム処理——具体的にはFFT(高速フーリエ変換)やチャネル推定、ビームフォーミング演算——をソフトウェアで賄う際の処理遅延だった。NVIDIAのCUDAコアを活用したGPUオフロードはこの壁を崩す技術的な突破口であり、MarvellのOCTEON 10 FusionはこのAerial SDKと親和性の高い設計になっている。
そしてこのエコシステム全体を支える標準化の根拠がO-RAN AllianceのSplit 7.2x仕様だ。
「O-RAN Allianceが定めるフロントホール仕様(Split 7.2x)への準拠により、マルチベンダー環境におけるRU(Radio Unit)とDU(Distributed Unit)の相互運用性が技術的に保証される」 ——出典: O-RAN Alliance Specifications
Split 7.2xとは、基地局をRU(アンテナ側)とDU(処理側)に機能分割する際の「どこで何を処理するか」の境界線を標準化したインターフェース仕様だ。この仕様への準拠が共通シリコンの前提条件となる。異なるベンダーのRUとDUを組み合わせ可能にすることで、初めて「共通チップ」が複数事業者・複数装置にわたってスケールする。
【比較表】従来アーキテクチャとのスペック比較
| 項目 | 従来型(カスタムASIC/垂直統合) | Marvell OCTEON 10 Fusion + NVIDIA Aerial |
|---|---|---|
| プロセスノード | 7nm〜(ベンダー非公開が多い) | 5nm |
| ワットあたり性能 | ベースライン | 最大3倍向上(旧世代比) |
| L1処理方式 | 専用DSP/ASIC | GPU(CUDA)オフロード対応 |
| ベンダー互換性 | 単一ベンダー内のみ | O-RAN Split 7.2x準拠でマルチベンダー対応 |
| vRAN対応 | 限定的(独自実装) | ネイティブ対応 |
| 導入モデル | ハードウェア一体型 | ディスアグリゲーション(機能分離)型 |
| 主なユースケース | 大規模マクロセル(既存5G) | vRAN、Open RAN、6Gへの移行パス |
【図解】技術アーキテクチャ・関係図
【考察】ITエコシステム・業界へのインパクト
1. EricssonとNokiaへの構造的圧力
MarvellとNVIDIAが連携して「共通シリコン+ソフトウェアL1」のスタックを確立すれば、EricssonやNokiaが長年かけて構築してきた「ハードウェアと最適化ソフトウェアの垂直統合」という参入障壁が技術的に解体される。通信事業者がMarvellチップを搭載した汎用サーバーとNVIDIA GPUを組み合わせてRANを構成できるなら、わざわざ高価な専用ハードウェアに縛られる理由がなくなる。
2. クラウドネイティブRANへの加速
このアーキテクチャが普及すれば、AWS、Google Cloud、Microsoft Azureといったハイパースケーラーがクラウド上でRAN機能を提供する「Cloud RAN」の実現可能性が一段と高まる。既にAWSはPrivate 5G、MicrosoftはAzure Operator Nexusを展開しているが、コモディティシリコンの普及はこれらのサービスのコスト競争力を根本から変える。
3. 半導体企業の通信インフラ進出
Marvellはインフラ向け半導体(Ethernet PHY、SSD コントローラ、DPU)で実績を持つが、RANのベースバンドは新領域だ。QualcommもRAN向けSoCを展開しており、「通信機器ベンダー対半導体ベンダー」という構図での競争軸の移動が加速する。NVIDIAにとっても、AIインフラとして蓄積したGPUのエコシステムを通信インフラへ横展開する戦略的な布石になる。
4. 6G移行への布石
現在のOpen RANの取り組みは5G NRを前提としているが、このソフトウェア定義・汎用シリコンベースのアーキテクチャは6Gのエアインターフェース(Tera-Hz帯域、AIネイティブ無線制御)への適応コストを大幅に下げる。ハードウェアを入れ替えずにソフトウェアアップデートで新機能に対応できる柔軟性は、6G展開において決定的な競争優位になり得る。
まとめ
MarvellがNVIDIAの支援を受けて提唱する「RAN共通シリコン」の動きは、通信インフラの歴史において「データセンターのx86化」に匹敵するパラダイムシフトの入り口に見える。
ただし、技術的な正当性と市場普及は別の話だ。O-RAN Split 7.2x準拠が保証する相互運用性は理論上の担保に過ぎず、実フィールドでの性能検証、電波法規制への対応、既存展開済みサイトのリプレースコストなど、商用展開には解決すべき課題が山積している。
EricssonとNokiaが単純にシェアを失うシナリオも短絡的だ。両社はすでにOpen RANへの対応を進めており、自社チップのコスト優位性が薄まれば、ソフトウェアとシステムインテグレーション能力にビジネスモデルを転換する方向性は十分にあり得る。
今見ておくべき指標は、「通信事業者が次の5G展開・6G試験でMarvell/NVIDIAベースのvRANを選択するかどうか」だ。そのファーストケースが出た瞬間、業界のシグナルは一気に変わる。
引用元記事・補足資料
Nvidia-backed Marvell pitches one chip to rule the RAN:本記事の一次情報源。MarvellがRAN向け共通シリコンの必要性を提唱した背景と市場戦略を報じるLight Readingの記事。
Marvell OCTEON 10 Fusion 5G ベースバンドプロセッサ:5nmプロセスと旧世代比3倍のワットパフォーマンスに関する公式仕様。本記事のスペック比較セクションの根拠。
NVIDIA Aerial SDK:GPU加速によるL1物理層オフロードの技術仕様。vRANにおけるNVIDIAのソフトウェアスタックの役割を裏付ける公式開発者ドキュメント。
O-RAN Alliance Specifications:Split 7.2xフロントホール仕様の標準化団体による公式仕様書。マルチベンダー相互運用性の技術的根拠として引用。


コメント