
【エグゼクティブ・サマリー】
- NVIDIAがカスタムASIC大手のMarvellに20億ドルを投資し、「NVLink Fusion」を通じた強固な提携を発表しました。
- これにより、ハイパースケーラー独自のカスタムチップ(XPU)が、NVIDIAの超広帯域・低遅延なネットワークエコシステムに直接統合可能となります。
- UALink陣営への強力な牽制となると同時に、次世代AIデータセンターにおけるインターコネクトのデファクトスタンダードを死守するNVIDIAのしたたかなプラットフォーム戦略が鮮明になりました。
既存テクノロジーの限界と課題
LLM(大規模言語モデル)の学習および推論フェーズにおいて、データセンター全体のボトルネックは「演算能力(Compute)」から「通信帯域(Interconnect)」へと明確にシフトしています。
従来、異なるベンダーのCPUやアクセラレータ間を接続するには、PCI Express(PCIe)規格が汎用的に用いられてきました。しかし、現在主流のPCIe Gen5(双方向128GB/s)や次世代のGen6をもってしても、AIワークロードにおける巨大なテンソルデータの同期や、ラックスケールでのメモリコヒーレンシを維持するには帯域幅が圧倒的に不足しており、通信遅延(レイテンシ)が深刻なオーバーヘッドを引き起こします。
この課題を解決するため、NVIDIAは独自プロトコルである「NVLink」を発展させ、自社製GPU間の超高速通信(双方向1.8TB/sなど)を実現してきました。一方で、AWS、Google、Microsoftなどのハイパースケーラー各社は、NVIDIA製GPUの供給不足やコスト、そして電力効率の観点から、自社専用のカスタムASIC(AI向けXPU)の開発を加速させています。
しかし、ここには構造的な「サイロ化」という罠がありました。他社製のカスタムXPUはNVLinkの閉鎖的なエコシステムに直接参加できず、標準的なイーサネットやInfiniBandを介したスケールアウト接続に頼らざるを得ないため、同一ラックスケール内での超高帯域なスケールアップ接続の恩恵をフルに受けることが物理的・アーキテクチャ的に不可能だったのです。
ニュースの核心とアーキテクチャの優位性
Tom’s Hardwareの報道によると、NVIDIAはカスタムASIC設計の雄であるMarvell Technologyに対して20億ドルの戦略的投資を実施し、「NVLink Fusion」を通じた広範なパートナーシップを締結したと発表しました。
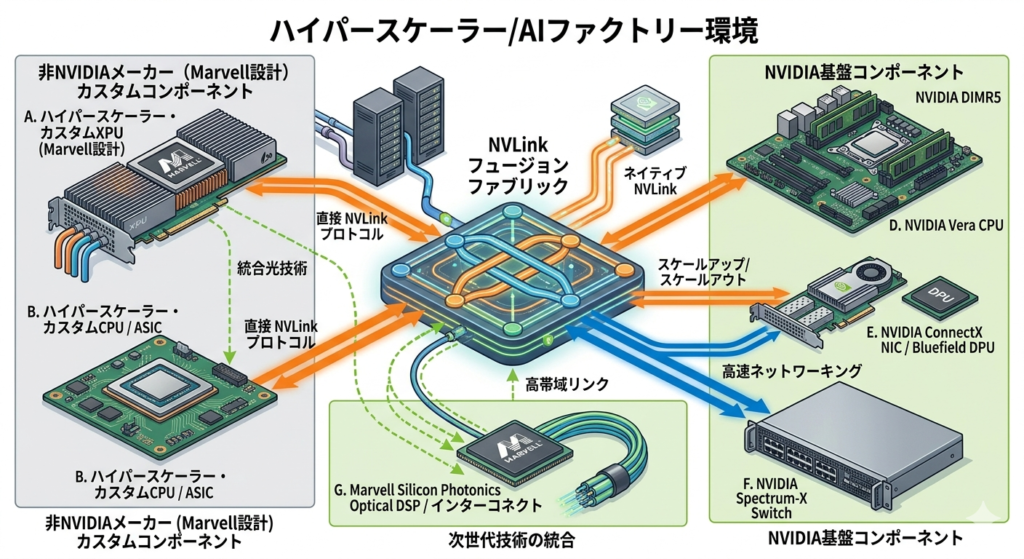
NVLink Fusionは、サードパーティ製のシリコン(XPU)をNVIDIAの独自インターコネクトファブリックであるNVLinkに直接接続可能にする革新的な技術プログラムです。これにより、異種混合(ヘテロジニアス)なAIインフラの構築が可能になります。
NVIDIAの創業者兼CEOであるJensen Huang氏は、今回の提携について以下のように述べています。
推論の変曲点が到来しました。トークン生成の需要は急増しており、世界はAIファクトリーの構築に向けて競い合っています。Marvellと共に、私たちは顧客がNVIDIAのAIインフラストラクチャ・エコシステムを活用し、特化したAIコンピューティングを構築して拡張できるよう支援します。
この提携におけるアーキテクチャの優位性は、強固な役割分担と統合にあります。
Marvell側は、各ハイパースケーラーの要件に特化した「カスタムXPU」と、先日買収したCelestial AIの技術を活かした「高速なシリコンフォトニクス(光電融合)インターコネクト」を提供します。対するNVIDIA側は、「Vera CPU」「ConnectX NIC」「Bluefield DPU」「Spectrum-Xスイッチ」、そしてインフラの背骨となる「NVLinkファブリック」を供給します。
さらに、Marvellの会長兼CEOであるMatt Murphy氏も以下の声明を出しています。
Marvellがリーダーシップを持つ高性能アナログ、光DSP、シリコンフォトニクス、そしてカスタムシリコンを、NVLink Fusionを通じてNVIDIAの拡大するAIエコシステムに接続することで、拡張性と効率性に優れたAIインフラストラクチャの構築を可能にします。
特筆すべきは、NVLink Fusionを利用するプラットフォームには**「最低でも1つのNVIDIA製品(CPU、GPU、またはスイッチ)を含めなければならない」**という仕様上の制約です。これにより、顧客がどれほど自社製のカスタムチップへ移行しようとも、基盤となるインフラの通信経路はNVIDIAのハードウェアとプロトコルが担うアーキテクチャが完成します。
【図解】技術アーキテクチャ・関係図
【エンジニア視点】ITエコシステム・業界へのインパクト
今回のNVIDIAの動きは「自らを破壊してでもプラットフォームの支配者であり続ける」という極めて高度な生存戦略です。
現在、Broadcom、AMD、Intelなどが主導し、AIチップ間の接続をオープンな標準規格にしようとする「UALink(Ultra Accelerator Link)」コンソーシアムが立ち上がっています。NVIDIAの独占を打破したいハイパースケーラーにとって、UALinkは魅力的な選択肢です。
NVIDIAがこれまで貫いてきた「自社製GPU・CPU・ネットワークの垂直統合による囲い込み(ウォールド・ガーデン)」は、長期的には顧客の反発(ベンダーロックインへの抵抗)を招き、UALink陣営への移行を加速させるリスクを孕んでいました。
そこでNVIDIAは、最大のASIC設計企業の一角であるMarvellを自陣営に取り込むことで、事実上「カスタムXPU市場に対するトロイの木馬」を放ちました。ハイパースケーラーは自社専用に最適化されたMarvell製カスタムASICを安価に手に入れつつ、NVIDIAの洗練された超低遅延ネットワーク(NVLinkやSpectrum-Xなど)の恩恵をそのまま享受できるようになります。
これは、顧客の「NVIDIA製GPU依存からの脱却」を許容する一方で、「NVIDIA製インターコネクト・インフラへの依存」を永遠に継続させるという、収益構造のパラダイムシフトです。
さらに、データセンターの物理的制約(電力密度と銅線の信号減衰)が限界に達している今、Marvellが保有するシリコンフォトニクス(光技術)へのアクセスを深めた点も見逃せません。近い将来、GPUやXPU間の通信は電気信号から光通信へと切り替わる必要がありますが、この光電融合アーキテクチャの標準仕様すらもNVIDIAが主導権を握るという強力なメッセージと言えます。
まとめ
NVIDIAによるMarvellへの20億ドルの投資とNVLink Fusionの提携深化は、単なる資金提供ではなく、次世代データセンターのネットワークトポロジーを定義する覇権争いの分水嶺です。
他社製のプロセッサであっても自社のファブリックに迎え入れるというオープン化の姿勢を見せつつ、その実、インフラの根幹たるネットワークスイッチやDPU、プロトコルをNVIDIAが掌握し続けるという構図は、極めて緻密な戦略です。我々インフラエンジニアは今後、GPUの演算性能(FLOPS)の比較以上に、「どのインターコネクト・ファブリックを採用し、どのようにシステム全体をスケールさせるか」というデータセンター全体のシステムデザインにおいて、さらに深い知見が求められることになるでしょう。


コメント