
【エグゼクティブ・サマリー】
- NVIDIAが発表したNeural Texture Compression(NTC)は、従来のブロック圧縮と比較してゲーム実行時のVRAM使用量を最大85%削減(6.5GB→970MB)しながら、視覚品質をほぼ完全に維持する
- 処理はGPU内のTensor Coreなどの行列演算専用ユニットにオフロードされるため、メインのシェーダー性能への影響はゼロに近い
- MicrosoftがDirectXのCooperative Vectorsとして標準化を進めており、NVIDIA・Intel・AMD全社のハードウェアで動作する業界共通規格に育ちつつある
既存テクノロジーの限界と課題
現代のゲームグラフィックスが直面するVRAM枯渇問題は、単なる「容量不足」ではなく、テクスチャ圧縮の構造的限界から来ている。
従来のブロック圧縮(BCn形式)の問題点
- 固定比率の呪縛:BC7などの標準フォーマットは4×4ピクセルブロック単位で圧縮するため、圧縮率はほぼ固定(元データの約25%)。素材の視覚的複雑度に関わらず同じ比率しか達成できない
- 精度の天井:ブロック内の色情報を限られたビット数で近似するため、グラデーションや法線マップの微細な変化が「ブロックノイズ」として劣化する
- MIPマップの多重コスト:遠距離LOD用に複数解像度のMIPマップを保持する必要があり、実際のVRAM消費はベーステクスチャの約1.33倍に膨らむ
- PBR素材の爆発的増加:Physically Based Rendering(PBR)の普及により、1素材あたりアルベド・ノーマル・メタルネス・ラフネス・アンビエントオクルージョンの5枚以上のテクスチャが束になって使われる。これが数百の素材に掛け算されると、VRAM消費は容易に数十GBに達する
- BRDFライティング計算のGPU負荷:各フレームでGPUはそれらのテクスチャを読み出し、Cook-TorranceなどのBRDF方程式に代入してピクセルごとに光の反射を計算する。これは演算リソースとメモリ帯域の両方を同時に圧迫する
ゲームの視覚的複雑度が上がるほど、この構造的な問題はより深刻になる。VRAM容量の物理的な増加(HBMの積層数拡大など)でカバーしようとするアプローチには、製造コストと電力密度の明確な上限がある。
ニュースの核心とアーキテクチャの優位性
Neural Texture Compression(NTC)の動作原理
NTCの本質は「テクスチャデータそのものをニューラルネットワークの重みとして圧縮する」という発想の転換にある。
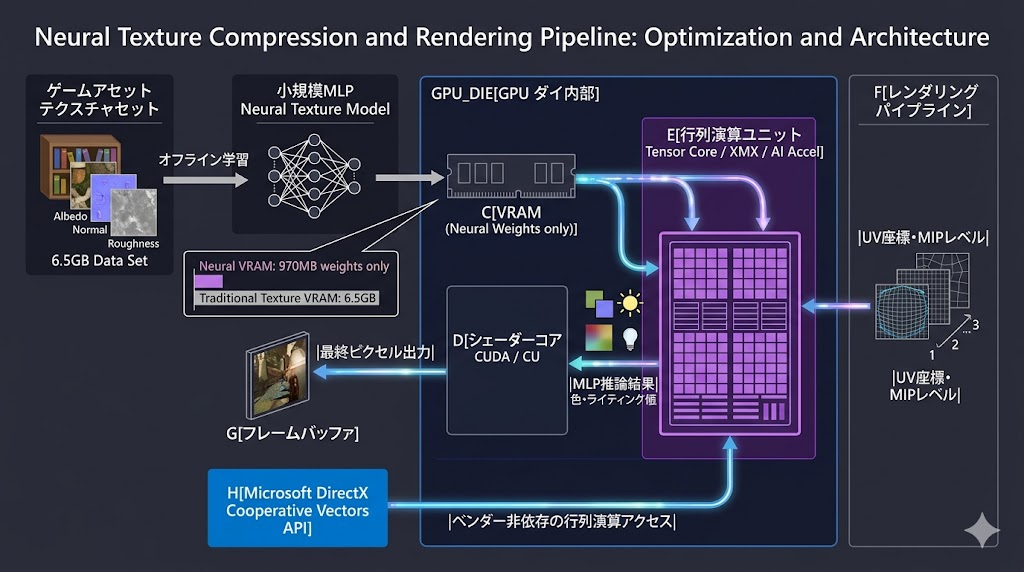
従来のBCnは「ピクセルデータをロスレスに近い形で圧縮して保存し、GPUで展開する」という方式だ。NTCはこれを根本から変え、小規模なMLP(多層パーセプトロン)をテクスチャセットに対してオフライン学習させ、そのモデルの重みだけをVRAMに保持する。
ゲーム実行時、GPUはテクスチャを「読み出して展開する」代わりに、そのMLPに対して「このUV座標・このMIPレベルでの色はどうなるか?」を推論させる。モデルはゲーム開発中にすでに全テクスチャデータを学習済みなので、幻覚(ハルシネーション)が発生する余地はない。
“NTC reduces that to just 970 MB, and the image looks identical.” — NVIDIA GTC Talk “Neural Texture Compression” (via Tom’s Hardware)
この学習は特定のゲームアセットに対してのみ行われるクローズドな学習であることが重要だ。汎用的なデータで訓練された生成AIとは根本的に性質が異なる。いわば「このテクスチャセット専用の超圧縮コーデック」を一つ訓練するイメージに近い。
Neural Materialsへの拡張
同じ思想はライティング計算にも適用できる。Neural Materialsは、BRDFの数式計算をMLPの推論に置き換える。
GPUが従来行っていた処理:
- アルベドテクスチャを読み込む
- ノーマルマップを読み込む
- ラフネス・メタルネスを読み込む
- Cook-Torrance BRDFで光源との相互作用を計算する
Neural Materialsが行う処理:
- MLPに「この光方向・視線方向でのライティング結果は?」を1回推論させる
“Neural Materials just asks the neural network how the light will react in that scenario and shades the pixel accordingly.” — Tom’s Hardware, 2026-04-04
NVIDIAの研究発表によると、1080p解像度でのベンチマークにおいて、この置き換えにより最大7.7倍の描画速度向上を確認している。
“up to 7.7x faster render times at 1080p resolution with no loss in image quality” — NVIDIA Research “Random-Access Neural Compression of Material Textures”
なぜ「ゲーム性能を下げずに」実現できるのか
NTCの推論処理はCUDAコアやROPではなく、Tensor Core(NVIDIA)、XMXエンジン(Intel)、AIアクセラレータ(AMD) といった行列演算専用のハードウェアブロックで実行される。これらはシェーダーや描画パイプラインとは独立したシリコン領域に配置されているため、通常のゲームレンダリング処理と並列動作できる。
DLSS・FSR・XeSSといったアップスケーラーも同じ専用ユニットを使っており、NTCはそのリソース空間に自然に収まる設計になっている。
業界標準化:Cooperative Vectorsとは
MicrosoftはこのNTCの基盤技術をDirectX 12の「Cooperative Vectors」として仕様化した。
“Microsoft has standardized it as ‘Cooperative Vectors’ in DirectX. Intel has previously shown off its own demo with noticeably better textures compared to block compression.” — Tom’s Hardware
出典:Microsoft DirectX Developer Blog “Agility SDK 1.714.0-preview: Cooperative Vectors” URL: https://devblogs.microsoft.com/directx/directx12-cooperative-vectors/
Cooperative Vectorsは行列演算ユニットへのAPIアクセスを標準化する仕様で、ベンダー固有のAPIを使わなくてもNVIDIA・Intel・AMD全社のAIアクセラレータをグラフィックスシェーダーから呼び出せるようになる。これによりゲームエンジン側はNTCを一度実装すれば全プラットフォームに対応できる。
【比較表】従来アーキテクチャとのスペック比較
| 項目 | 標準ブロック圧縮(BC7等) | Neural Texture Compression(NTC) |
|---|---|---|
| VRAM使用量(Tuscan Villaシーン) | 6.5 GB | 970 MB(約85%削減) |
| VRAM使用量(フライトヘルメット) | 98 MB | 11.37 MB(約88%削減) |
| 圧縮比率 | 固定(元の約25%) | 可変・内容依存(元の約5〜10%も可能) |
| ライティング計算方式 | BRDF数式(Cook-Torrance等) | MLP推論による代替 |
| 描画速度(Neural Materials) | ベースライン | 最大7.7倍高速(1080p) |
| 処理ユニット | シェーダーコア(CUDA/CU) | 行列演算専用ユニット(Tensor Core等) |
| ハルシネーションリスク | なし(決定論的) | なし(特定アセットのみで学習) |
| API標準化 | BCnフォーマット(広く普及) | Cooperative Vectors(DirectX / 普及はこれから) |
| ゲームサポート現状 | 全タイトルで使用中 | 現時点でゼロ(実装待ち) |
【図解】技術アーキテクチャ・関係図
【エンジニア視点】ITエコシステム・業界へのインパクト
HBM供給問題とコスト構造への影響
NVIDIAがTensor CoreをAI推論からグラフィックスへ積極的に活用する背景には、HBM(High Bandwidth Memory)の供給制約とコストという現実がある。HBMはSK HynixとMicronの製造能力に強く依存しており、価格も通常のGDDR6Xと比べて桁違いに高い。
NTCが普及すれば、同一の視覚クオリティをより少ないVRAMで達成できる。これはGPUベンダーにとって「搭載するVRAMの量を増やさずに高品質グラフィックスを実現できる」という製品設計上の自由度につながる。HBM需要の一部を直接代替するポテンシャルを持つ技術だ。
ゲームエンジンへの実装コストとエコシステムの変化
Cooperative Vectorsの標準化により、Unreal Engine・Unity等の主要エンジンがNTCをプラグイン的に組み込む経路ができた。開発者はDirectX 12のAPIを通じてベンダー非依存でNTCの推論処理を呼び出せるため、NVIDIA専用の実装を書かずに済む。
ただし、実際のゲームへの採用にはゲームアセット制作パイプラインの変更が必要になる。テクスチャアーティストが従来のBCnエクスポートの代わりに、NTCのMLP学習パイプラインをビルドプロセスに組み込む必要があるため、ツールチェーンの整備が普及速度を左右する。
AI推論シリコンの「目的外利用」という大きな流れ
NTCはより広いトレンドの一部でもある。AI推論用に積まれた行列演算ユニットを、グラフィックスのメモリ・演算問題を解くために転用するという方向性は、DLSSのアップスケーリングから始まり、NTCのテクスチャ圧縮、そしてNeural Materialsのライティング計算代替へと拡張されつつある。
このことは、将来のGPUアーキテクチャにおけるTensor Core比率の設計指針にも影響する。ゲーミングGPUにおいて、Tensor Coreはもはや「AI機能のオマケ」ではなく、コアなレンダリングパスの一部として機能し始めている。
AMDとIntelの対応状況と競争力学
MicrosoftのCooperative Vectors標準化はNVIDIAに有利に働く一方で、IntelとAMDにとっては「追いつくための共通の土台」を与えてくれる仕様でもある。
- Intel:XMXエンジンを搭載するArc GPUでのNTC対応デモを既に公開済み
- AMD:2024年時点でCooperative Vectorsに言及しているが、具体的な実装デモはまだ少ない
- NVIDIA:Tensor Coreの世代が深く、既存のMLライブラリ・ツールチェーンとの親和性が最も高い
短期的にはNVIDIAの先行優位が続くが、Cooperative Vectorsという共通APIが普及するにつれ、差別化のポイントはハードウェアの行列演算性能だけでなく、開発者向けツールチェーンとアセット制作パイプラインの質に移っていく可能性が高い。
まとめ
NTCが示したのは、「VRAMは物理的に積み増すしかない」という前提が崩れ始めているという事実だ。6.5GBのテクスチャデータを970MBのMLPの重みに変換して同等の品質を出す、というアプローチは、メモリ帯域とキャパシティに依存してきた従来のレンダリングアーキテクチャの設計哲学を根底から揺さぶる。
現時点でNTCをサポートするゲームタイトルはゼロだ。しかしDirectXレベルでCooperative Vectorsとして標準化されたことで、次のUnreal Engine / Unityのメジャーバージョンアップがこれを取り込むかどうかが、普及の分水嶺になる。そのタイミングが来たとき、GPUの「実効VRAM容量」の概念は数字の読み方ごと変わっているだろう。
引用元記事・補足資料
Nvidia AI tech claims to slash gaming GPU memory usage by 85% with zero quality loss — Neural Texture Compression demo reveals stunning visual parity between 6.5GB of VRAM and 970MB:Tom’s Hardware によるGTC発表のレポート記事。Tuscan Villaシーンにおける6.5GB→970MBのデモ、Neural MaterialsのBRDF代替デモ、Cooperative Vectorsの業界標準化動向を網羅した本記事の主要情報源。
Random-Access Neural Compression of Material Textures – NVIDIA Research:NTCおよびNeural Materialsの技術的基盤を示すNVIDIA公式研究論文。1080pでの7.7倍高速化データの一次ソース。
Agility SDK 1.714.0-preview: Cooperative Vectors – Microsoft DirectX Developer Blog:DirectX 12における「Cooperative Vectors」仕様の公式解説。NTCがNVIDIA専用でなく、Intel・AMD含む全GPUベンダー対応の業界標準として進んでいることを裏付ける。


コメント