
【エグゼクティブ・サマリー】
NVIDIA GTC 2026の会場で、AivresはVera Rubin世代の完全液冷ラック「NVL72(KRS8000V4)」を実機展示した。本ラックは従来世代で煩雑だったケーブル配線を一掃し、GPU・CPU・ネットワーク・SSDをすべて液冷で統合するORv3規格準拠の設計を採用している。さらに次世代DPU「BlueField-4」はKVキャッシュ管理をCPUからオフロードする能力を大幅に強化しており、LLM推論の効率化とデータセンター全体の電力対性能比の向上を同時に実現するアーキテクチャとして注目される。
既存テクノロジーの限界と課題
AIワークロードが急速に重量化するにつれ、従来のサーバーラック設計は複数の物理的・構造的な壁に直面してきた。
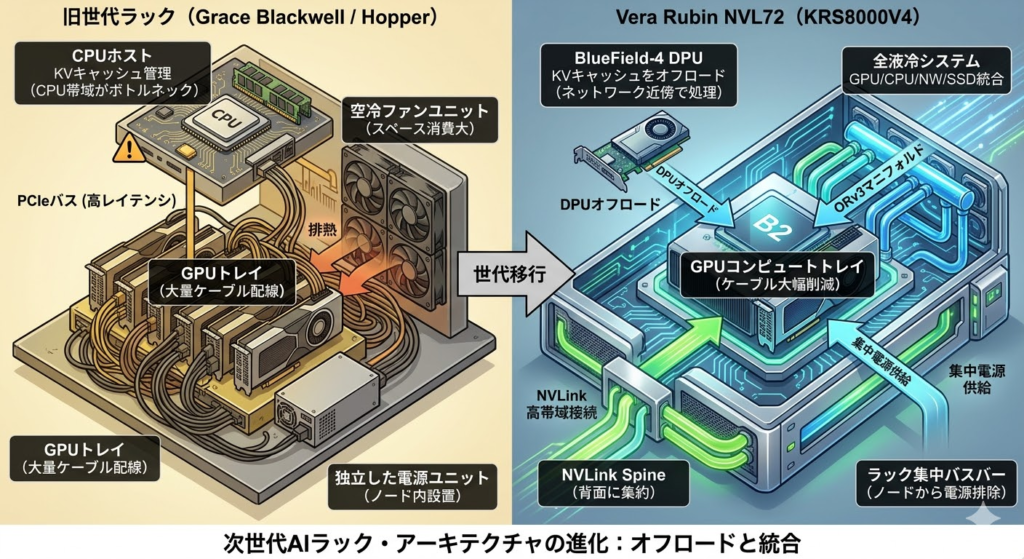
まず空冷(Air Cooling)の熱密度限界だ。1ラックあたりの消費電力がBlackwell世代で120kWを超え始めると、空気という媒体の熱容量では到底追いつかない。空気の体積熱容量は水の約3,400分の1であり、ファンの回転数をいくら上げても物理法則は覆せない。加えて大型ファンユニットはラック内スペースを圧迫し、実効的なコンピュート密度を下げるという本末転倒な結果を招く。
次にケーブリングの複雑性とサービス性の問題だ。前世代までのHopperやBlackwellラックでは、GPUトレイ・NVLinkスイッチ・ストレージ・ネットワークをつなぐ大量の銅線ケーブルが、ラック内部を迷路のように占拠していた。これは組み立て工数の増大だけでなく、フィールドでの障害切り分けを著しく困難にし、MTTRを悪化させる要因となっていた。
そしてLLM推論におけるKVキャッシュのボトルネックがある。Transformerモデルが推論中に生成するKey-Valueキャッシュは、シーケンス長に比例してメモリを爆食いする。このキャッシュ管理をホストCPUが担う従来の設計では、CPUのメモリ帯域幅と処理能力がLLMスループットの頭打ちを引き起こしていた。データが「計算」を待つのではなく、「キャッシュ管理」の順番待ちをするという構造的非効率が、大規模クラスターの実効性能を数十パーセント単位で削っていたのだ。
ニュースの核心とアーキテクチャの優位性
ServeTheHomeの2026年3月28日付報道によると、NVIDIA GTC 2026の展示会場でAivresはVera Rubin世代の完全液冷ラックを公開した。
「ブースでAivresは、KRS8000V4という型番のNVIDIA Vera Rubin NVL72ラックを展示していた。これはVera RubinコンピュートトレイとシNVLinkスイッチトレイを単一のORv3ラックに統合した、液冷対応ラックだ。」
同レポートが特筆するのは、コンピュートトレイを単体で見た際に前世代に比べてケーブルが劇的に削減されている点だ。これはNVLinkの接続をNVLink Spineとして背面に集約し、個々のGPUトレイから引き回す信号線を最小化したアーキテクチャによるものと考えられる。
「GPUs、CPU、ネットワーキング、そしてSSDのすべてが液冷されている。より高い密度をラックに詰め込むための、さらなる統合レベルだ。」
また電源設計の変更も重要な変更点だ。各サーバーノードから電源ユニットを排除し、ラックレベルのバスバーに集約することで、ノード内のスペースをコンピュートとネットワーキングに全振りできる設計になっている。これは電力変換効率の向上にも直結する。
ストレージレイアウトの変更についても同報告は言及している。Grace BlackwellラックとVera Rubinラックを並べて観察すると、Vera Rubin側のストレージの配置が液冷を容易にする形に変更されていることが確認できるという。
さらに、同展示においてBlueField-4 DPUも展示されていた。
「このBlueField-4世代はコンピュートとメモリが大幅に増強されており、KVキャッシュ管理のようなタスクを処理できるようになっている。」
このDPUによるオフロードは、ホストCPUを解放するだけでなく、DPU自身がネットワークファブリックに近い位置でキャッシュを管理できるため、レイテンシプロファイル自体を根本から変える可能性を持つ。
【図解】技術アーキテクチャ・関係図
【エンジニア視点】ITエコシステム・業界へのインパクト
液冷の「標準化」がもたらすインフラ調達の構造変化
今回のVera Rubin NVL72に見られる最も重要な変化の一つは、液冷が「オプション」ではなく「前提」になった点だ。ラック内にファンパーティションが存在しないという設計は、後から空冷に戻す選択肢を物理的に閉ざしている。これはデータセンターオペレーター側に、冷却水配管(CDU: Coolant Distribution Unit)とORv3準拠のマニフォルドを標準インフラとして整備することを半ば強制する。つまり、SMCIやVertivのような液冷ラックソリューションプロバイダーの需要が、NVIDIAのハードウェアサイクルと連動して押し上げられる構造が強固になったと解釈できる。
BlueField-4 DPUが変えるソフトウェアスタックの設計思想
KVキャッシュ管理をDPUにオフロードするという方向性は、単なるハードウェアの話ではない。これはLLM推論エンジン(vLLM、TensorRT-LLM等)のメモリ管理ロジックが、DPUのプログラミングモデルを意識して設計される必要が生じることを意味する。将来的には、DPUのローカルメモリとGPU HBMの間でKVキャッシュをインテリジェントにページングするレイヤーが、推論スタックの中核に位置付けられる可能性がある。オープンソースの推論フレームワーク開発者コミュニティにとって、このDPU-GPU協調設計への対応は次の重要な技術的課題となるはずだ。
電源設計の変化がデータセンター電力インフラに与える影響
ノードレベルからラックレベルへの電源集約(バスバー方式)は、従来の48V DCバスに対して異なる変換段数と電力品質要件をもたらす可能性がある。これはUPS(無停電電源装置)やPDU(電力分配ユニット)の設計仕様にも波及し、電力インフラ側のアーキテクチャの刷新を促す。一台のラックが100kWを超える消費電力を持つ状況では、ラック単位の電力計測・管理の粒度も従来とは異なる精度が求められるようになる。
ORv3規格の普及と相互運用性
Open Rack v3(ORv3)への準拠を前提としたラック設計は、コロケーション事業者やハイパースケーラーが施設規格をORv3に揃える動機をさらに強める。かつてはGooglee・Meta・Microsoftといった大手が独自規格を持っていたが、AI計算の大規模化と液冷の必須化という二つの圧力が、業界全体を共通規格へと収束させつつある。Vera Rubinの実機公開は、その収束速度を加速するシグナルとして機能するだろう。
まとめ
NVIDIA GTC 2026で公開されたVera Rubin NVL72の実機は、単なる性能向上のアップデートではなく、AIデータセンターの物理設計における根本的なパラダイムシフトを体現している。完全液冷・ケーブル大幅削減・電源集約・DPUによるKVキャッシュオフロードという四つの変化は、それぞれが独立したトレンドではなく、「より高い計算密度を、より少ない物理的リソースで実現する」という一つの設計哲学から派生したものだ。エンジニアとして注目すべきは、このハードウェアの変化が、推論ソフトウェアスタック・冷却インフラ調達・データセンター電力設計という三つの領域に同時に波及する連鎖的なインパクトを持つ点である。Vera Rubin世代が量産フェーズに移行するにつれ、これらの変化は急速に「業界標準」へと昇格していくだろう。


コメント