
【エグゼクティブ・サマリー】
- NVIDIAが強化学習(RL)ベースのシステム「NB-Cell」を導入し、エンジニア8名×10ヶ月を要していた標準セルライブラリ移植作業を、GPU1基で一晩に短縮した
- 社内専用LLM「ChipNeMo」「Bug Nemo」が設計文書やRTLコードで訓練され、ジュニアエンジニアのメンターとして機能、シニアエンジニアの工数を大幅に削減している
- AIが算出した回路設計は「人間では思いつかない奇抜な構造」でありながら、面積・電力・性能(PPA)で人間設計比20〜30%優れるという結果が出ている
既存テクノロジーの限界と課題
半導体設計は、現代のテクノロジー産業の中でも最もリードタイムが長い工程の一つだ。その根本的な原因は、設計の複雑さが指数関数的に増大し続けている一方で、人間の認知能力と作業時間には物理的な上限があることにある。
具体的なボトルネックを整理すると、次のとおりだ。
- 標準セルライブラリの移植コスト爆発: 新しい製造プロセス(例:TSMCの新世代ノード)に移行するたびに、回路の基本部品(標準セル)を一から再設計・最適化する必要がある。これだけで熟練エンジニア8名が10ヶ月、つまり延べ80人月を消費していた
- 設計検証(Verification)の長大な工程: チップ開発サイクルの中で最も時間を食う工程の一つ。バグを見つけるためのテストケースを網羅的に作成・実行する作業は、現在もAIで完全代替できていない
- アーキテクチャ探索の試行錯誤: チップ開発初期の「どんな設計方針で行くか」という意思決定は、経験豊富なシニアエンジニアへの依存度が高く、知識の属人化が深刻なボトルネックになっていた
- 先端プロセス移行コストの高騰: 3nmや2nmといった最先端ノードになるほど、設計ルールが複雑になり、設計コストは前世代比で数倍規模に膨らむ傾向がある
これらの課題は、単純に人員を増やせば解決する性質のものではない。チップ設計は並列化しにくい知識集約型の作業であり、「人を増やす」という解決策に限界があることは、業界内では長年の共通認識だった。
ニュースの核心
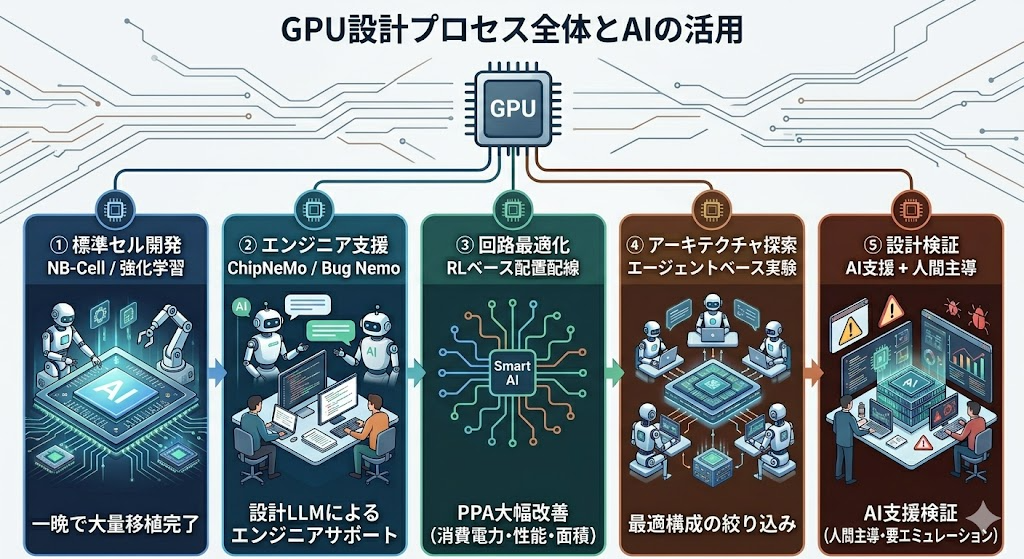
NVIDIAのAI活用マップ:4つの設計レイヤー
NVIDIAのCTOにあたるチーフサイエンティスト、William Dally氏は、Googleの Jeff Dean氏との対話の中でAI活用の全体像を明かした。同社はチップ設計の最低レベルから最上位レベルまで、4つの階層すべてでAIを適用している。
① 標準セル開発レベル(最低レベル):NB-Cell
ここで登場する「標準セル」とは、チップを構成する最小単位の電気回路部品のことだ。レゴブロックに例えると分かりやすい——チップ設計者はこの「ブロックの種類と仕様書(ライブラリ)」を新しい製造プロセスに合わせて作り直す必要がある。2,500〜3,000種類のブロックすべてを人手で最適化するのが、例の「エンジニア8名×10ヶ月」という作業だ。
NVIDIAが開発したNB-Cellは、強化学習(RL)(※AIが試行錯誤を繰り返して最適解を探す機械学習手法)を使い、この作業をGPU1基で一晩に短縮した。
② エンジニアリング支援レベル:ChipNeMo / Bug Nemo
これが特に興味深い。NVIDIAは汎用LLM(※ChatGPTのような大規模言語モデル)をベースに、社外に一切出ていない社内データで徹底的にファインチューニング(※特定用途向けに追加学習させること)した専用モデルを構築した。
学習データの内容:
- NVIDIAがこれまでに開発した全GPUのRTLコード(※Register Transfer Level:ハードウェアの動作を記述するコード)
- 全GPU向けのアーキテクチャ仕様書
- 社内のハードウェア設計ドキュメントの全量
このモデルの役割は、「24時間365日対応できる忍耐強いシニアエンジニア」だ。Dally氏はこう表現している。
“When you have a junior designer, they can ask Chip Nemo, and Chip Nemo will explain [how GPUs work]. It improves productivity that way; it is a very patient mentor.” ——William Dally, NVIDIA Chief Scientist(出典:Tom’s Hardware, 2026年4月)
ジュニアエンジニアの「これどういう仕組みですか?」という質問を、シニアエンジニアの代わりにChipNeMoが引き受ける。シニアエンジニアはより高度な意思決定に集中できる、という構造だ。
③ 回路設計最適化レベル:RLベース設計システム
強化学習を用いたシステムが、配置・配線(Place & Route)(※回路部品をシリコン上のどこに置き、どう繋ぐかを決める工程)の最適解を探索する。その結果として生まれる設計は、
“It comes up with totally bizarre designs that no human would ever come up with, but they are actually 20% or 30% better than the human designs.” ——William Dally(出典:Tom’s Hardware, 2026年4月)
人間の設計者が「それは無いだろう」と直感的に排除してしまうような、常識外れの構造をAIは躊躇なく試す。その結果として、PPA(※電力・性能・面積のトレードオフを示す半導体設計の重要指標)で20〜30%の改善を達成している。
④ アーキテクチャ探索レベル:エージェントベースシステム
開発の最上流フェーズ、つまり「どんなアーキテクチャで次世代GPUを設計するか」という意思決定においても、AIエージェントが大量の実験を並列実行し、有望な設計方向を絞り込む役割を担っている。これは人間のチームが行う「アーキテクチャレビュー会議」の高速版と考えると分かりやすい。
「完全自律設計」はまだ遠い
注目すべきは、Dally氏が明確に限界も認めている点だ。
“I would love to have the end-to-end stage where I could simply say, ‘design me the new GPU,’ but I think we are a long way from that.”
特に設計検証(Design Verification)は、AIによる完全代替が最も難しい工程として挙げられている。実際に動作するハードウェアを使ったエミュレーションや実験は、現時点では省略できない。
長期的なビジョンとして、Dally氏は「専門特化した複数のAIエージェントがチームのように連携して設計を担うマルチエージェントモデル」を描いている。
【比較表】従来アーキテクチャとのスペック比較
| 評価項目 | 従来手法(人間エンジニア) | AI活用手法(NVIDIA現行) |
|---|---|---|
| 標準セル移植工数 | エンジニア8名 × 10ヶ月(= 約80人月) | GPU 1基 × 一晩 |
| PPA最適化性能 | ベースライン(人間設計) | 人間比 +20〜30% 改善 |
| 知識アクセス | シニアエンジニアへの質問が必要 | ChipNeMoに即時問い合わせ可能 |
| アーキテクチャ探索 | 少数の選択肢を人間が評価 | AIエージェントが大量並列実験で探索 |
| 設計検証 | 人間主導・長期間必要 | AI支援中(完全代替は未達) |
| 完全自律設計 | 人間が全工程を主導 | 不可(現時点) |
【図解】技術アーキテクチャ・関係図
【考察】ITエコシステム・業界へのインパクト
競合他社への圧力:EDAがコアコンピタンスになる
今回の開示が業界に与える最大のシグナルは、EDA(電子設計自動化)(※半導体設計を支援するソフトウェアと手法の総称)が単なる生産性向上ツールを超え、競合との差別化を決定づけるコア技術になりつつあるという点だ。
AMD、Broadcom(AVGO)といった競合他社も、AIを用いた設計効率化を推進しているが、NVIDIAの優位性は「自社製品の設計データ」という参入障壁が極めて高い学習データ資産にある。ChipNeMoが「NVIDIAがこれまでに作った全GPUのRTL」で訓練されているという事実は、他社が同等のモデルを構築しようとしても、単純には追いつけないことを意味している。
TSMCなどファウンドリへの影響
先端プロセスへの移行コストが半導体設計の最大の障壁の一つだったが、標準セル移植の自動化はその障壁を大幅に引き下げる。結果として、プロセス世代の更新サイクルが加速し、TSMCへの発注タイミングや生産計画にも影響を及ぼす可能性がある。
インフラエンジニアへの示唆
「AIがチップを設計する」という話は一見、インフラエンジニアには遠い世界の話に聞こえるかもしれない。しかし視点を変えると、このトレンドはインフラ設計そのものにも同じ圧力がかかり始めていることの先行事例だ。ネットワーク構成の自動最適化、サーバーリソース配置の強化学習による探索——これらはすでに研究段階から実用段階へ移行しつつある。NVIDIAのチップ設計AIは、インフラ自動化の「5年後の姿」を示している。
EDAベンダーへの構造的影響
SynopsysやCadenceといった既存のEDAベンダー(※半導体設計ソフトウェアを提供する企業)にとって、NVIDIAが自社開発のAI設計システムを持つことは脅威でもあり機会でもある。大手チップメーカーが内製化を進める一方で、中小設計会社向けにAI-EDAを提供するビジネスモデルは強化される可能性がある。
まとめ
NVIDIAが今回開示した内容を整理すると、同社のAI活用は「生産性の向上」という表現では著しく過小評価される。80人月の作業を一晩に圧縮するという数字は、設計コストの構造そのものを書き換えている。
重要なのは、これが将来の話ではなく現在進行形の実装であるという点だ。NB-CellもChipNeMoも、すでに現役のGPU開発プロセスで稼働している。「完全自律設計はまだ遠い」というDally氏の発言は、現実的な技術認識として誠実だが、裏を返せば「設計検証の自動化が解けた瞬間」に、次の大きなブレークスルーが来ることを示唆している。
引用元記事・補足資料
Nvidia says AI cuts 10-month, eight-engineer GPU design task to overnight job:Tom’s Hardwareによる本件の一次報道記事。Dally氏の発言を直接引用。
Silicon Volley: Designers Tap Generative AI for a Chip Assist(NVIDIA公式ブログ):NVIDIAブログによるChipNeMo概要記事。NB-Cellによる標準セル移植自動化の背景を解説。
ChipNeMo: Domain-Adapted LLMs for Chip Design(NVIDIA Research):NVIDIA公式研究ページ。ChipNeMoのドメイン適応手法と評価結果を掲載。
ChipNeMo: Domain-Adapted LLMs for Chip Design(arXiv:2311.00176):ChipNeMoのアーキテクチャとドメイン適応手法を詳述した研究論文(査読前プレプリント)。


コメント