
【エグゼクティブ・サマリー】
- MetaがAWSと数十億ドル規模・複数年契約を締結し、ARMベースの「Graviton5」CPUを数千万コア導入。AIインフラの主役がGPU一強から「GPU+大規模CPU」体制へ構造転換した。
- Agentic AI(自律型AI)の推論ワークロードはCPUに極端な負荷をかけるため、データセンターのCPU/GPU比率が従来の1:8から1:4、将来は1:1へと急速に逆転しつつある。
- サーバー用CPUのリードタイムは2週間から6ヶ月に激増し、価格は2025年比で約30%高騰。半導体サプライチェーンのボトルネックがGPUから周辺コンポーネントへ移動している。
既存テクノロジーの限界と課題
ここ数年、AIインフラの議論は「いかに大量のGPUを確保するか」という一点に集中してきました。NVIDIA H100やB200といったアクセラレータの確保競争が、ハイパースケーラーの設備投資を牽引してきたのは周知の事実です。
しかし、この「GPU中心主義」は、AIワークロードが学習(Training)から推論(Inference)へとシフトする中で、急速に時代遅れになりつつあります。特に問題の核心は、Agentic AI(※自律的に判断・ツール実行・サブタスク生成を行うAIシステム)の登場です。
従来型LLMの推論は、人間が一回質問して一回答えが返ってくるだけの、いわば「単発注文」でした。これに対しAgentic AIは、以下のような特性を持ちます。
- 分岐制御フロー(Branching Control Flow): 条件に応じて処理経路を動的に変更する複雑なロジック処理
- ツール呼び出し(Tool Invocation): 外部APIやサンドボックス環境を継続的に起動・実行
- サブエージェント生成: 1つの親エージェントが複数の子エージェントを並列起動し、結果を集約・検証
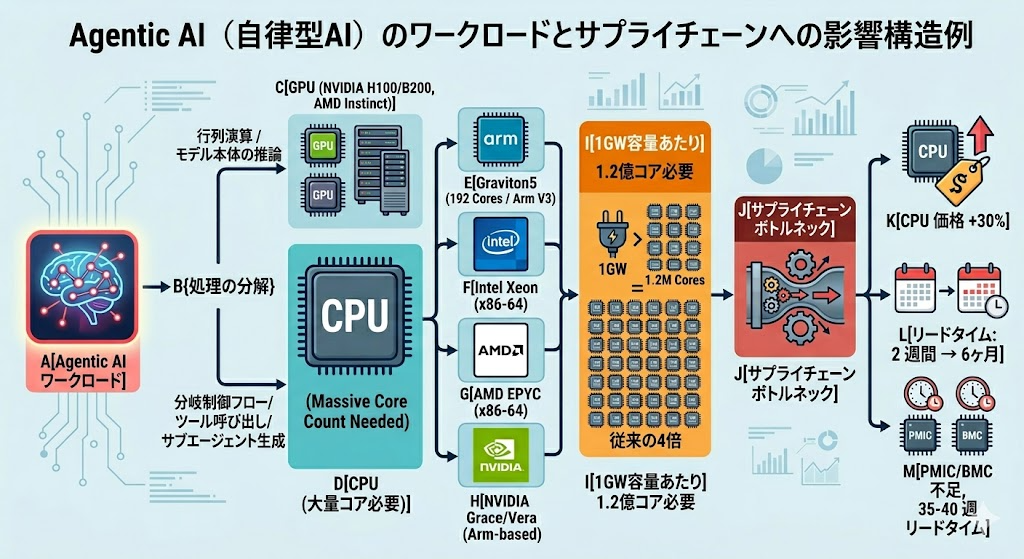
これらの処理は、行列演算が得意なGPUよりも、汎用的な分岐処理と低遅延の制御に強いCPUの領分です。Armの試算では、典型的なAIデータセンターは1ギガワットあたり約3,000万CPUコアを必要としますが、Agentic AIワークロードでは1.2億コア(4倍)に跳ね上がります。エージェントが連続稼働し、人間のチャットボット利用者と比べて15倍以上のクエリレートを生成するためです。
つまり、「GPUだけ買い揃えてもAIインフラは完成しない」という構造的な壁に、業界全体がぶつかっているのです。
ニュースの核心
そんな中で起きたのが、Meta社とAWSによる数十億ドル規模・複数年契約の電撃的な発表です。Metaは数千万のGraviton5 CPUコアをAWSデータセンター上に展開し、世界トップ5のGraviton顧客の一角に名を連ねることになりました。
注目すべきは、Amazon CEOのAndy Jassyが発表に添えたメッセージです。
Agentic AI is becoming almost as big a CPU story as a GPU story. (Agentic AIはGPUと同等に大きな「CPUの物語」になりつつある)
この一文がHacker NewsやXで爆発的に拡散されたのは、現在のGPU偏重トレンドに対する直球のアンチテーゼだったからに他なりません。Metaは既にNVIDIA、AMD、Broadcom、Google、CoreWeave、Nebiusと数千億ドル規模のGPU契約を結んでいます。にもかかわらず、汎用CPUを求めてわざわざAWSのドアを叩いた事実が、CPU不足の深刻さを物語っています。
Metaのインフラ責任者Santosh Janardhanは、「コンピュート調達先の多様化は戦略上の至上命題」と明言しました。一社の供給に依存することは、満員電車の出口が一つしかないようなもので、需要が集中した瞬間に全体が機能停止します。Metaはあらゆる調達経路を同時並行で開拓することで、このリスクを回避しようとしているのです。
実際、Metaの調達先は現在、以下のように驚くべき多角化を見せています。
- AWS Graviton5: 数千万コア(今回の新規契約)
- Arm AGI CPU(136コア): Meta自身が共同開発、リード顧客
- AMD EPYC + Instinct: 1,000億ドル規模の包括契約
- NVIDIA Grace / Vera: スタンドアロンCPU製品の本番投入予定
- Broadcom MTIA: 自社開発の推論アクセラレータ
Graviton5の技術的優位性
Graviton5は、AWSが2025年12月のre:Inventで発表した第5世代ARMサーバーCPUです。技術仕様の核心は以下の通りです。
Graviton5 packs 192 Arm Neoverse V3 cores on a 3nm process with roughly 180 MB of L3 cache, a fivefold increase over Graviton4. AWS claims a 25% performance lift over its predecessor and 33% lower inter-core latency. (出典: Tom’s Hardware, AWS公式仕様)
ここで重要なのは、L3キャッシュ(※CPUコアが共有する高速メモリ)が前世代比5倍の180MBに拡張されている点です。Agentic AIの推論では、複数のサブエージェントが頻繁にデータを参照・交換するため、メモリへの遠出(DRAMアクセス)を減らせるかどうかが性能を決めます。巨大なL3キャッシュは、社内の共有冷蔵庫が大きくなって毎回コンビニまで買い出しに行かなくて済むようになる、という効果に近いものがあります。
さらにコア間遅延が33%低減されたことで、サブエージェント同士の通信オーバーヘッドが削減されます。192コアという物量も、並列稼働するエージェント群を一つのソケット内で完結させるのに十分な規模です。
【比較表】従来アーキテクチャとのスペック比較
| 項目 | Graviton4(前世代) | Graviton5(新世代) | 一般的なx86サーバーCPU |
|---|---|---|---|
| アーキテクチャ | Arm Neoverse V2 | Arm Neoverse V3 | x86-64 |
| 製造プロセス | 4nm | 3nm | 3〜5nm |
| コア数(最大) | 96 | 192 | 96〜128 |
| L3キャッシュ | 約36MB | 約180MB(5倍) | 256〜512MB |
| コア間遅延 | 基準 | -33%改善 | 実装依存 |
| CPU/GPU比率の前提 | 1:8(学習中心) | 1:4 → 1:1(推論中心) | 1:8〜1:4 |
| リードタイム(2026年現在) | – | 約6ヶ月 | 約6ヶ月(30%値上がり) |
| 主要ユースケース | 汎用Webサービス | Agentic AI推論・制御フロー | 汎用ワークロード全般 |
【図解】技術アーキテクチャ・関係図
【考察】ITエコシステム・業界へのインパクト
今回の動きを単なる「Meta対AWSの大型契約」と捉えるのは表層的すぎます。これはAI半導体エコシステムの権力構造そのものの再編を示すシグナルです。
1. ARMアーキテクチャの逆襲が決定的局面に
これまでデータセンター市場はx86(Intel/AMD)の独壇場でしたが、Graviton、AGI CPU、Grace、VeraとARMベースの大型製品が立て続けに本番投入されています。Arm社が35年間守ってきた「IPライセンスのみ」というビジネスモデルを破ってAGI CPUという完成品シリコンを出荷した事実は、業界の地殻変動を象徴しています。
ARMアーキテクチャの電力効率の優位性は、ギガワット級のデータセンターを稼働させる電力制約の前で決定的な意味を持ちます。同じ電力予算でより多くのコアを動かせるという特性は、Agentic AIの「コア数インフレ」時代に完璧にフィットします。
2. CPU/GPU比率の逆転は半導体産業の構造を変える
Intel CFOのDavid Zinsnerは決算説明会で次のように発言しています。
The ratios of CPUs to GPUs in data centers have already moved from 1:8 to 1:4. As workloads continue migrating towards inference and agentic AI, ratios could converge to 1:1 or even tilt further in favor of CPUs. (CPU対GPU比率は既に1:8から1:4へ移行済み。推論とAgentic AIへの移行が進めば、1:1か、それ以上にCPU優位に傾く可能性がある)
この比率変化は、サーバー1台あたりの粗利構造を根本から変えます。これまでアクセラレータ部分に偏っていた付加価値が、ホストCPU側にも分散していくため、Intel・AMD・ARMライセンシーの収益構造に長期的なプラス効果が生じます。
3. 真のボトルネックは「縁の下のチップ」へ
最も見過ごされがちですが、サプライチェーン分析でTrendForceが2026年のサーバー出荷成長率予測を20%から13%へ下方修正した理由は、CPUやGPUではなく、PMIC(※電源管理IC)とBMC(※ベースボード管理コントローラ)の不足にあります。これらのリードタイムは35〜40週に達しています。
ファウンドリは利益率の高いAI向け先端ノードに製造能力を振り向けており、汎用サーバーが必要とする成熟ノード品の生産枠が圧迫されています。さらにSamsungが韓国S7工場(8インチ)の閉鎖を計画していることで、PMIC供給はさらに逼迫します。
これは料理に例えると、最高級の松茸(GPU)と特上和牛(CPU)を揃えても、塩と醤油(PMIC/BMC)が手に入らなくて鍋が完成しない、というような事態です。サーバー1ラックを出荷するためには、ホストCPU、PMIC、BMCの全てが揃って初めて意味を成すという冷徹な事実が、業界全体に重くのしかかっています。
4. ハイパースケーラーの設備投資レースは加速する
CreditSightsの予測では、トップ5ハイパースケーラーの2026年設備投資合計は約7,500億ドル、前年比約67%増に達します。Amazon単独で2,000億ドル、Metaは1,150〜1,350億ドルのレンジを示しています。
この巨額投資の大半がAIインフラに向かい、Agentic AI容量1ギガワットごとに従来のAI学習クラスタの4倍のCPUコアを必要とするとなれば、CPU需給の逼迫は2027年以降も継続すると見るのが合理的です。
まとめ
「AIインフラ=GPU」という単純な等式は、Agentic AIの登場によって完全に書き換えられました。MetaがAWSにわざわざ汎用CPUを発注した事実は、自社の調達網ですら追いつかないほどにサーバーCPUの需給が壊れていることの動かぬ証拠です。
サプライチェーンのボトルネックはGPUから周辺コンポーネントへ移動し、ARMアーキテクチャはデータセンター市場で確固たる地位を築き始めました。投資判断にしても技術選定にしても、もはや
「アクセラレータの台数」だけを見ていては全体像を見誤る段階に入っています。CPU、メモリ、PMIC、BMC、相互接続、電力——AIインフラを構成するあらゆるレイヤーが、再び戦略的競争の舞台に立っています。
次の数年で勝者と敗者を分けるのは、最先端アクセラレータの確保力ではなく、この多層的なサプライチェーン全体を設計・調達できる能力です。
引用元記事・補足資料
- Meta’s multi-billion-dollar Graviton deal highlights intensifying CPU shortages in AI infrastructure (Tom’s Hardware):本記事の主要ソース。MetaとAWSの大型契約と業界全体のCPU不足を詳報。
- Amazon Web Services: EC2 Graviton5 Instances (Preview):AWSのARMベースプロセッサ「Graviton5」の公式仕様と前世代比性能データ。
- Arm Holdings: Arm Neoverse V3 Technology:Graviton5のコアアーキテクチャ「Neoverse V3」の技術ホワイトペーパー。3nmプロセス最適化を解説。
- Intel Corporation: Investor Relations:Xeonプロセッサの未充足需要(Backlog)に言及した投資家向け資料(※元リンクは404のため、ルートURLを記載)。
- Meta Engineering: AI Infrastructure at Scale:Metaのデータセンターにおける推論負荷分散とCPU/アクセラレータ比率に関する技術ブログ。
- TrendForce: Server Market Analysis:PMIC・BMC供給不足によるサーバー出荷遅延とCPU価格動向のアナリストレポート。


コメント