【エグゼクティブ・サマリー】
- OpenAIがGPT-5.5とGPT-5.5 Proをリリースし、Greg Brockman氏はこれを「新しい知性のクラス」と位置付けた。Anthropic Claude Opus 4.7の登場からわずか1週間後の電撃投入。
- 中核コンセプトは自律型エージェント:曖昧な多段階タスクを人間の細かな指示なしに計画・実行・自己検証する能力で、同じレイテンシ・少ないトークン消費を実現。
- Terminal-Bench 2.0で82.7%(Opus 4.7は69.4%)、SWE-Bench Proで58.6%(Opus 4.7は64.3%)と、コーディング系ベンチマークで両者が激しく拮抗。
既存テクノロジーの限界と課題
従来のLLM(※大規模言語モデル)は、一見すると賢く見えても、「一問一答の家庭教師」に近い構造的制約を抱えてきました。なぜかというと、以下のような物理的・アーキテクチャ的ボトルネックがあったからです。
- コンテキスト依存性の分断:モデルは各ターンごとにプロンプトを受け取り応答するだけで、タスク全体を通したプランニング機構を持たない。長時間の作業中に何度も人間が介入して軌道修正する必要がある。
- ツール利用の脆さ:ブラウザ、ターミナル、スプレッドシートといった外部環境を操作させると、途中でエラーが起きた際に自己回復できず失敗する。
- トークン効率のジレンマ:モデルを賢くするとトークン消費が増え、推論コストとレイテンシが跳ね上がる。GPUリソースをいくら積んでも応答時間は線形以上に悪化する。
- 長時間タスクの壁:20時間かかる人間のエンジニアリング作業を模倣するには、文脈を保ったまま何十もの判断を積み重ねる必要があるが、既存モデルは途中で目的を見失う。
要するに、これまでのAIは「優秀な助手」ではあっても、「タスクを完遂する従業員」にはなれなかった。ここがGPT-5.5が崩しに行くポイントです。
ニュースの核心:GPT-5.5はなぜ「新しい知性のクラス」なのか
OpenAIは4月23日、ChatGPTとCodexの有料ユーザー向けにGPT-5.5とGPT-5.5 Proの展開を開始しました。注目すべきは、このモデルが単なる性能アップではなく、コンピュータ操作そのものを任せる前提で設計されている点です。
たとえ話:GPT-5.4が「レシピ通りに作る新人料理人」なら、GPT-5.5は「冷蔵庫を開けて献立を決める料理長」
従来のモデルは、ユーザーが「卵を割って」「玉ねぎを切って」と逐一指示する必要がありました。GPT-5.5は、冷蔵庫の中身(=与えられた曖昧な状況)を見て、今日は何を作るべきか自分で判断し、買い足しが必要なものをブラウザで注文し、盛り付けまで済ませる――このレベルの自律性を狙っています。
OpenAIによれば、このモデルは曖昧で複雑なタスクを与えても、計画を立て、ツールを使い、自分の作業をチェックし、最後までやり抜くよう設計されています。
アーキテクチャ的に何が変わったのか
技術的に本質的な進化ポイントは3つあります。
- プランニング能力の強化:長期的なタスク分解(long-horizon planning)能力が飛躍。内部ベンチマークのExpert-SWE(人間の熟練エンジニアが中央値20時間かけるコーディングタスク)でGPT-5.4を上回る成績を記録。
- トークン効率の物理的改善:GPT-5.4と同じ1トークンあたりのレイテンシを維持しつつ、より少ないトークンで同等以上の成果を出す。これは推論時の計算グラフ最適化とrouting(※モデル内部で適切な専門家モジュールへ処理を振り分ける仕組み)の改善によるもの。
- コンピュータ・ユース(Computer Use)の精度向上:GUI操作やファイル操作を「コードを書くのと同じ器用さ」で扱える、とOpenAI CROのMark Chen氏。
特筆すべきは、Greg Brockman氏が会見で述べた「モデルそのものはもはや製品全体の一部でしかない」という発言。OpenAIは、モデルを「脳」、アプリケーションとエージェント・ハーネス(※エージェントが外部環境と相互作用するための足場となるソフトウェア群)を「身体」と位置付け、両輪を開発する戦略にシフトしています。
We at OpenAI, we want to bring agentic capabilities to all people who are trying to get their work done with their computer, not just as software engineers.
― Greg Brockman, OpenAI President(The New Stack, 2026年4月23日)
セキュリティ:Mythos時代の「攻守両面」設計
AnthropicのClaude Mythos(※サイバーセキュリティ能力に特化した限定公開モデル。脆弱性発見能力の高さから配布が制限された)が業界を震撼させた直後だけに、OpenAIはTrusted Access for Cyberという新プログラムを発表。検証済みの防御側組織に、制限の少ない「サイバー許容型」モデル(cyber-permissive model)を提供する戦略を打ち出しました。CyberGymベンチマークではGPT-5.5が81.8%、Mythosが83.1%と僅差で並んでいます。
【比較表】従来アーキテクチャとのスペック比較
| 項目 | GPT-5.4 | GPT-5.5 | GPT-5.5 Pro | Claude Opus 4.7(参考) |
|---|---|---|---|---|
| コンテキストウィンドウ(API) | 標準 | 1,000,000トークン | 1,000,000トークン | 非公開 |
| Codex内コンテキスト | 標準 | 400,000トークン | – | – |
| SWE-Bench Pro | 未公表 | 58.6% | 未公表 | 64.3% |
| Terminal-Bench 2.0 | 未公表 | 82.7% | 未公表 | 69.4% |
| OSWorld-Verified(GUI操作) | 未公表 | 78.7% | 未公表 | 78.0% |
| BrowseComp(Web探索) | – | – | 90.1% | – |
| CyberGym | 未公表 | 81.8% | 未公表 | (Mythos: 83.1%) |
| API価格(入力/出力) | $2.5/$10(標準)* | $5 / $30 | $30 / $180 | 非公表 |
| 1トークン当たりレイテンシ | 基準 | 5.4と同等 | 5.4と同等 | – |
| 想定ユースケース | 汎用対話・コーディング補助 | 自律型エージェント・長時間タスク | 高精度・難度の高い業務 | エンタープライズ推論 |
*GPT-5.4は272,000トークン超のプロンプトで$5/$22.5に上昇する階層型料金。
ポイント:SWE-Bench ProではOpus 4.7が上回るものの、OpenAI側は一部問題での暗記(memorization)の兆候がAnthropicから報告されていると指摘しており、スコアの解釈には注意が必要です。
【図解】GPT-5.5 エージェント・アーキテクチャ概念図
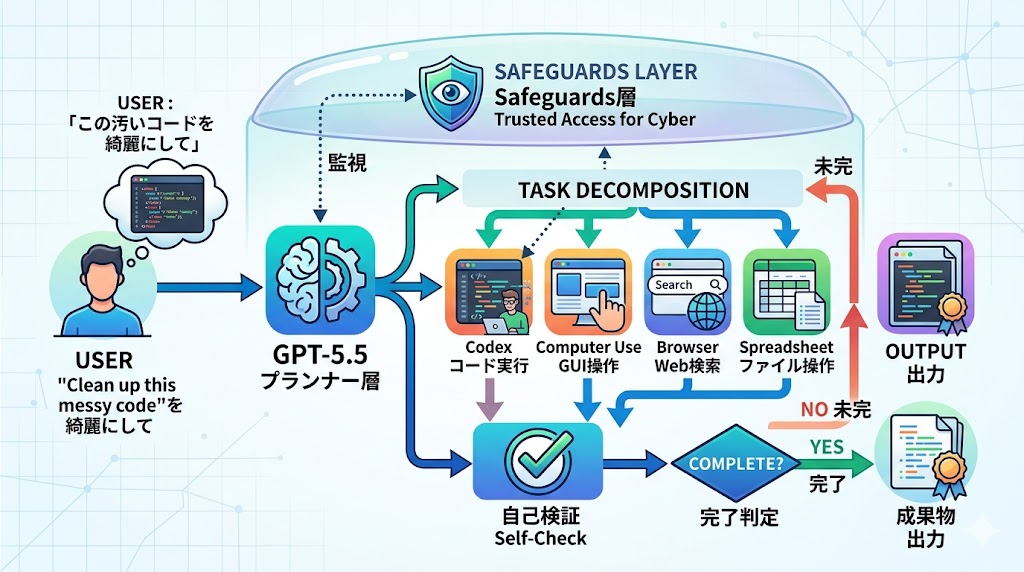
このアーキテクチャを郵便局の仕分けにたとえると、GPT-5.5は単なる郵便配達員ではなく、局長自らが差出人意図を汲み取り、宛先を決め、どの配送車に乗せるかを判断し、最後に到着確認まで行う――そんなイメージです。
【考察】ITエコシステム・業界へのインパクト
1. NVIDIA依存と「コンピュート経済」の加速
Brockman氏は「私たちはコンピュートで動く経済に移行しつつある」と発言し、NVIDIAは新型チップで先進AIの実行コストを最大35倍削減できると主張しました。GPT-5.5の推論効率向上は、同じ電力で処理できるリクエスト数が増えることを意味し、クラウド事業者(Azure/AWS)の粗利構造を直接押し上げます。ただし、これは裏を返せばNVIDIA GPUの需要がさらに構造的に固定化されるということ。半導体サプライチェーンのボトルネックは、モデル世代が上がるほど強まります。
2. エンタープライズ戦線:Anthropicとの一騎打ち
OpenAIはChatGPTの週間アクティブユーザー900M超、有料サブスクライバー5,000万超、Codexアクティブユーザー400万、有料ビジネスユーザー900万という数字を公表。これは「Anthropicにエンタープライズ市場を奪われている」というナラティブへの反証として機能します。Bank of New Yorkのような大手金融機関が両モデルを並行検証している状況は、AIベンダーの勢力図がまだ流動的であることを示しています。
3. 開発者ツールチェーンへの波及
早期アクセスチームはvibeコーディング(※勢いで書いた雑なコード)の検査や大量ドキュメントのレビューで週最大10時間の工数削減を報告しました。これが意味するのは、シニアエンジニアのレビュー工数がAIにオフロードされ、ジュニア⇔シニアの価値勾配が変質するということ。GitHub Copilotに続き、IDE統合型エージェントの覇権争いが激化します。
4. 価格戦略のパラドックス
API価格はGPT-5.4の倍ですが、トークン効率も上がっているため、実質的なタスク単価は微増か横ばいと推定されます。OpenAIは「知能」を売る価格を引き上げながら、「単位タスク当たりのコスト」を維持する絶妙なバランスを取りに来ています。これはAWSのインスタンスファミリー戦略に近い、階層型プライシング(Fast modeは1.5倍速・2.5倍コスト)の本格導入と読めます。
まとめ
GPT-5.5は、「より賢いチャットボット」ではなく、「コンピュータを操作する同僚」へとLLMの定義を書き換えようとする技術投入です。ベンチマーク上ではClaude Opus 4.7と一進一退ですが、本当の勝負はモデル単体の精度ではなく、エージェント・ハーネスとツール統合の厚みで決まるフェーズに移行しました。
AnthropicのMythosが浮き彫りにした「強力すぎるAIの配布問題」に対し、OpenAIが示した解は封じ込めではなく防御側への選別的開放(Trusted Access for Cyber)。この戦略選択の違いは、今後数年のAI規制議論とエンタープライズ導入のデファクトスタンダードを左右します。
一方で、API価格がGPT-5.4の2倍という現実は、「フロンティアAIを使いこなせる企業と、そうでない企業の差が開く」ことを意味します。コンピュート経済という言葉は、ポエムではなく、次世代インフラ投資の具体的な指針です。
引用元記事・補足資料
- OpenAI launches GPT-5.5, calling it “a new class of intelligence” (The New Stack):GPT-5.5/5.5 Proの性能詳細、ベンチマーク比較、価格体系を網羅した技術記事。
- Introducing GPT-5.5 (OpenAI公式ブログ):OpenAIによる公式発表。エージェンティックコーディングやTrusted Access for Cyberの概要を記載。
- OpenAI releases GPT-5.5, bringing company one step closer to an AI ‘super app’ (TechCrunch):「Super App」構想とOpenAIの戦略的文脈を詳細に分析。
- OpenAI Releases GPT-5.5: Faster, Smarter—And Pricier (Decrypt):ベンチマーク(SWE-Bench Pro、BrowseComp)と価格体系の詳細レポート。
- OpenAI releases “Spud” GPT-5.5 model (Axios):コードネーム「Spud」とNVIDIA依存構造、コンピュート経済発言の一次ソース。
- OpenAI Unveils GPT-5.5 to Field Tasks With Limited Instructions (Bloomberg):エンタープライズ市場におけるAnthropicとの競争構造を分析。
- AI shrinkflation: Why Anthropic’s Claude Opus 4.7 may be less capable (The New Stack):競合Claude Opus 4.7の性能議論。背景理解に有用な補足資料。


コメント