
【エグゼクティブ・サマリー】
- Metaが米国従業員のPCにMCI(Model Capability Initiative)を配備し、マウス・キー・スクリーンショットを収集してAIエージェントの学習データにすると発表
- 従来のLLM(※大規模言語モデル)が苦手な「ドロップダウン選択」「ショートカットキー」といったGUI操作の模倣を狙う技術的必然性が背景にある
- CTOは「オプトアウト不可」と明言し、インターネット上の公開データが枯渇した今、企業内部の行動ログが新たな「油田」として争奪戦化している
既存テクノロジーの限界と課題
現行のLLMは文章生成こそ驚異的な性能を発揮しますが、「コンピュータを人間のように操作する」という領域では致命的に弱いことが、業界全体の課題として表面化しています。
- テキスト空間と操作空間のギャップ:LLMは文字列(トークン)の連続予測で訓練されていますが、GUI操作は「座標」「タイミング」「視覚的状態」といった非テキスト情報の上に成立します。
- 中間状態の欠落:ユーザーが「プルダウンを開く → ホバーで3番目を選ぶ → クリック」という動作の途中の状態は、完成した文章ログには一切残りません。
- ネガティブサンプルの不在:ウェブ上のスクレイピングデータには「なぜその選択肢を選ばなかったのか」という情報が含まれず、判断根拠の学習が不可能です。
- データ枯渇(Data Wall)問題:高品質な公開テキストはほぼ学習し尽くされ、新規性のある大規模データセットの確保が各社の戦略課題になっています。
ここで浮上したのが、「人間が実際にPCを操作しているログそのものを学習データにする」というアプローチです。Metaはこれを自社従業員で実行することを決断しました。
ニュースの核心:MCIとは何をするツールか
Metaは米国従業員のPCに新たなトラッキングソフトを導入し、マウスの動き、クリック、キー入力、さらには画面のスクリーンショットを定期的に取得してAIモデルの訓練データとして利用します。 このツールはModel Capability Initiative(MCI)と呼ばれ、業務用アプリと特定のウェブサイト上でのみ動作します。
これを直感的に理解するには、「料理番組の撮影」をイメージすると分かりやすいです。
レシピ本(=テキストデータ)を読んでも、「炒め物の火加減」「混ぜる速度」「鍋を振るタイミング」は身につきません。プロの料理人が実際に作っている様子を真横から長時間撮影し続けることで、初めて弟子はその「暗黙知」を模倣できます。MCIは、Metaエージェントにとっての「料理番組カメラ」そのものです。
ここで登場する中核技術が行動模倣学習(Imitation Learning)(※人間の行動データを教師信号として、AIに操作手順そのものを学ばせる手法)です。従来の強化学習が「正解のない環境で試行錯誤」を繰り返すのに対し、模倣学習は「熟練者のデモ」から出発するため、学習効率が桁違いに高いのが特徴です。
なぜ「従業員の手」が必要なのか
MetaのCTOであるAndrew Bosworth氏は、従業員向けメモでこの取り組みの最終目標を次のように明示しました。
「私たちが目指すビジョンは、エージェントが主に作業を行い、私たちの役割はそれを指示し、レビューし、改善を助けることだ」
つまりMCIは、単なるログ収集ではなく「エージェントが人間の仕事を引き継ぐための教材」を、人間自身に生成させるプロジェクトです。Metaは昨年データラベリング企業Scale AIの株式49%を140億ドル超で取得し、元Scale AI CEOのAlexandr WangがMeta Superintelligence Labsを率いています。 データ収集能力そのものを、外部調達から自社のコアコンピタンスへと再定義した動きとして読み解けます。
従業員の反発とオプトアウト不可問題
ソース記事によれば、社内では強い反発が起きており、「オプトアウトはできるのか?」という従業員の質問に対し、Bosworth氏は「業務用ラップトップでオプトアウトする選択肢はない」と断言しました。Yale大学のIfeoma Ajunwa法学教授は、米国連邦法には従業員監視を制限する規定がないと指摘しています。
技術的には、Microsoftが消費者向けに展開したRecall機能(※Windowsに搭載されたスクリーンショット自動記録機能)と似た仕組みですが、決定的な違いがあります。
- Recall:ローカル保存・ユーザー自身の検索用途・ユーザーが消去可能
- MCI:集中収集・AI訓練用途・従業員による削除は不可
【比較表】従来アーキテクチャとのスペック比較
| 項目 | 従来LLM(テキスト特化) | Vision-Language Agent(例:初期Computer Use) | MCI型模倣学習エージェント |
|---|---|---|---|
| 学習データソース | Web上の公開テキスト | スクリーンショット+合成操作データ | 実業務の連続ログ(生データ) |
| 操作の正確性 | 低(座標認識が不安定) | 中(静的判断に偏る) | 高(動的な操作列を学習) |
| ドロップダウン・ショートカット | 苦手 | 条件付きで可能 | 実デモから直接学習 |
| レイテンシ要件 | テキスト応答のみ | 数秒〜数十秒 | 人間並みの応答速度を志向 |
| データ枯渇リスク | 高(既存Web消費済) | 中 | 低(業務が続く限り生成) |
| プライバシーコスト | 低 | 中 | 極めて高(常時監視) |
| 代表的ユースケース | チャット、要約 | 簡単なWeb操作 | ホワイトカラー業務の自動化 |
【図解】技術アーキテクチャ・関係図
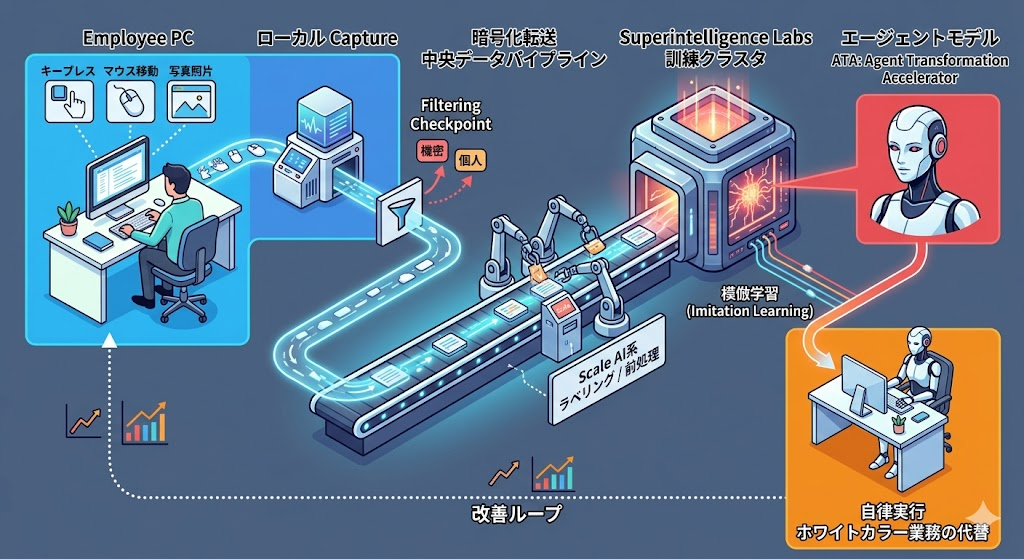
【考察】ITエコシステム・業界へのインパクト
MCIの登場は、AI業界のデータ調達戦略と労働構造の両面に地殻変動をもたらします。
データ調達のパラダイムシフト
これまでの「Web上の公開データを大量スクレイピング」という手法は、著作権訴訟とデータ枯渇の二重苦で限界に達しています。各社が次に向かう先は「独占的かつ高品質な行動ログの囲い込み」であり、その最短ルートが自社従業員のログ収集です。
- Microsoft:OfficeとGitHub Copilotの操作ログを既に活用可能な構造
- Google:Workspaceの利用データ(ただしBtoB契約上の制約あり)
- OpenAI:契約ライターからの業務成果物収集(Handshake AI経由)
- Meta:MCIでゼロ距離の操作ログに踏み込む
インフラ側への波及
常時スクリーンショットと操作ログを収集するということは、1従業員あたり数MB〜数十MB/日のログが発生する計算になります。Meta規模(米国従業員数万人)では1日で数TBクラスの新規学習データが供給され続け、これを処理するストレージとGPU訓練パイプラインの設計は、従来の「バッチ学習」とは異なる継続学習(Continual Learning)アーキテクチャが求められます。Meta Superintelligence Labsの訓練クラスタが抱える要件は、もはやNVIDIA H/B系GPUの単純な積み増しでは追いつかず、データIngestion層の再設計が不可避です。
規制と地政学的分断
EUおよび英国のデータ保護法では、同等の措置には明示的な法的根拠と従業員の同意が必要となるため、Metaは米国内のみでMCIを運用しています。 これは「AIエージェントの学習データ収集において、米国が事実上の規制回避地として機能する」構造を意味し、今後EUが追加の規制を打ち出せば、訓練データそのものの地政学リスクが顕在化します。
自己参照型の労働リスク
最も鋭い論点は、「従業員が自分の代替者を訓練している」という自己参照性です。Metaは同時期に最大20%規模のレイオフを計画していると複数メディアが報じており、MCIのデータで育ったエージェントが、データを提供した本人のポジションを埋めるシナリオが現実味を帯びます。これはエンジニアリング倫理ではなく、労働法制の根本を問う問題に発展する可能性が極めて高いです。
まとめ
MCIは「プライバシー侵害の新事例」として語られがちですが、技術者視点で見れば「GUIを操作できるAIを作るには、もはや実環境の連続ログを吸い上げるしか道がない」という、モデル開発側の追い詰められた状況を露呈した事件です。公開データの時代は終わり、企業内部の業務プロセスそのものが次世代モデルの競争資源となった。オプトアウト不可という一文が意味するのは、米国の労働法の空白が、そのままAI企業の戦略的優位性に転換されているという事実です。データセンターに流れ込むのは電気だけではなく、今や人間の作業そのものになりました。
引用元記事・補足資料
- Now Meta will track what employees do on their computers to train its AI agents(The Verge):Metaが社内ツール「MCI」で従業員操作を収集する件を、CTOのメモと内部反発を交えて報じた主要記事。
- Meta to start capturing employee mouse movements, keystrokes for AI training data(Reuters配信・KSL):Reuters原報道の全文を掲載。Yale大学Ajunwa教授の法的コメントを含む一次情報に最も近い記事。
- Meta will start tracking employees’ screens and keystrokes to train AI tools(Fortune):Scale AI買収(140億ドル)とAlexandr Wangの役割、2026年の1,350億ドル設備投資計画との関連を解説。
- Meta will record employees’ keystrokes and use it to train its AI models(TechCrunch):業界全体のトレーニングデータ枯渇問題の文脈で解釈した技術系メディアの報道。
- Meta is installing tracking software on US employees’ computers(The Next Web):EU・英国法制との比較、MCIが米国限定である地政学的意味を詳述。
- Microsoft Recall Privacy & Security Documentation(Microsoft Learn):MCIと類似技術であるMicrosoft Recallの公式ドキュメント。ローカル収集型との設計思想の違いを比較する一次資料。
- Meta Superintelligence Labs 公式ページ(Meta AI):Alexandr Wangが率いるSuperintelligence Labsの研究発信拠点。


コメント