
【エグゼクティブ・サマリー】
- SpaceXがAIコーディングIDE「Cursor」に対し、年内に600億ドルで買収する権利、または100億ドルの提携料を支払う異例のオプション契約を取得
- 結合の要はxAI/SpaceXが運用する推定20万GPU規模の「Colossus」。Cursorは事実上、世界最大級の学習インフラを手に入れる
- 「AIによるAI開発」を加速させる構図が固まり、MSFT(GitHub Copilot)、NVDA、TSMCを巻き込む開発者ツール覇権の再編が始まる
既存テクノロジーの限界と課題
今回のニュースを正しく読むには、まず「なぜCursorがここまで巨大な計算資源を必要とするのか」を構造的に捉える必要があります。AIコーディングアシスタントが直面している壁は、単なる「もっと賢いモデルが欲しい」という話ではありません。
1. コンテキストウィンドウという物理的な天井 現行のAIコーディングツールは、モデルが一度に扱えるトークン数(※文字や単語の最小単位)に制約されます。数十万行規模のモノレポ(※巨大な単一リポジトリ)を横断的に理解するには、モデルに投入する情報量もそれを処理する計算資源も桁違いに必要になります。これは「車線数が2つしかない高速道路に、深夜トラック1万台を流し込もうとしている」状況に近く、どれだけ運転手(モデル)が優秀でも道路(計算基盤)がボトルネックになります。
2. 強化学習(RL)による後工程の計算飢餓 近年のコーディングモデルは、事前学習後に大規模な強化学習ポストトレーニングを走らせることで精度を伸ばしています。コードを生成 → 実行 → テスト結果を報酬シグナルとしてモデルを再学習、というループを何百万回も回すため、推論と学習が同時進行する混成ワークロードになります。これは従来の「学習は専用クラスタ、推論はエッジ」という分業モデルを壊します。
3. N×M統合問題とエージェント化 AIコーディングは単体のチャット補完から、外部ツール・DB・社内システムを操作するエージェントへと進化しています。ところが連携するツールごとに専用コネクタを書くと、AnthropicがN×M問題と呼ぶ指数的な統合コストが発生します。これが後述するMCP採用の背景です。
4. ハイパースケーラー依存というサプライチェーンリスク 多くのAIスタートアップはAWS、Azure、GCPのGPU枠を奪い合う構造にあり、計算資源の確保が競争上の最大変数になっています。自社で学習インフラを持つ者が勝つという「Compute is the new moat」構造が強まっています。
ニュースの核心
何が起きたのか
2026年4月21日(現地時間)、SpaceXがX上で異例の提携スキームを公表しました。要点は次の3つです。
- SpaceXとCursorが共同でコーディング/ナレッジワーク向けAIを開発
- xAI/SpaceXが運用する「Colossus」はH100相当で100万GPUへのロードマップを持つ世界最大級のAI学習スーパーコンピュータで、CursorはこれをフルにAI学習に活用
- SpaceXは年内にCursorを600億ドルで買収する権利を持ち、買収しない場合でも100億ドルを「共同作業の対価」として支払う
SpaceX自身の発表から核となる部分を引用します。
Cursor has also given SpaceX the right to acquire Cursor later this year for $60 billion or pay $10 billion for our work together.
通常、M&A交渉が不成立になった際に支払うブレイクアップ・フィーは買収総額の3〜5%程度が相場です。600億ドルに対する100億ドルは約16.7%と異常に高く、しかも「決裂時の違約金」ではなく「共同作業の対価」として位置づけられている点が本件のユニークさを象徴しています。
「Colossus」とは何か──1秒間に4京回計算する怪物を理解する
Colossusはイーロン・マスク率いるxAIが米国テネシー州メンフィスに構築した、旧Electrolux工場を転用したAI学習データセンターです。構成を整理します。
- 2025年12月時点の構成は、H100 15万基、H200 5万基、GB200 3万基を単一の一貫した学習クラスタとして統合
- H100単体でHBM2e 80GB・2TB/sのメモリ帯域、FP8で約4PFLOPSの性能を持ち、Blackwell GB200では1基あたり20PFLOPSに到達
- NVIDIA Spectrum-Xイーサネットで10万基規模のHopper GPUを液冷接続
- 電力需要は膨大で、Teslaの168台のMegapackバッテリー蓄電で電力変動を吸収するハイブリッド給電を採用
これは「巨大な郵便局の仕分けセンター」にたとえると分かりやすいです。1つひとつのGPUが「仕分け係(処理する職員)」で、Spectrum-X Ethernetが「センター内の高速ベルトコンベア」です。普通のイーサネットでは複数台を繋ぐほど詰まりが発生しますが、Spectrum-XはRDMA(※メモリを直接読み書きする通信方式)やアダプティブルーティングで95%近いスループットを維持し、10万人規模の仕分け係を遊ばせずに働かせ続けることを可能にしています。
MCPがなぜ鍵になるのか
今回の提携でもう一つの主役となるのがMCP(Model Context Protocol/※AIエージェントと外部ツールを繋ぐ標準プロトコル)です。
- MCPはAnthropicが2024年11月に発表したオープン標準で、JSON-RPC 2.0をトランスポートとしてLSP(Language Server Protocol)の思想を踏襲
- CursorやWindsurfなどのIDEはMCPサーバのセットアップをワンクリック化しており、開発者ツール領域での普及が先行
- MCP launch以降、コミュニティが構築したMCPサーバは数千規模に達し、業界のデファクト標準となっている
MCPは「料理のレシピで言う計量単位の国際規格化」に近い役割を担います。グラム、ミリリットル、カップが統一されていれば、どの国のシェフでも同じレシピを再現できます。同様にMCPが統一されれば、CursorがGitHub、Jira、Slack、社内DBなど「どんな材料(外部データソース)」と連携するにも、毎回専用の翻訳機(カスタムコネクタ)を書き起こす必要がなくなります。
この標準があって初めて、Cursorは単なるコード補完ツールから「コードベース全体を読み、テストを実行し、Slackで報告するエージェント」へとスケールできるわけです。Colossusで訓練された高性能モデル × MCPで繋がった無数のツール、というスタックが完成します。
【比較表】従来アーキテクチャとのスペック比較
| 項目 | GitHub Copilot(現行・MSFT系) | Cursor × Colossus(本件結合後) |
|---|---|---|
| 主要学習インフラ | Microsoft Azure(OpenAIクラスタ) | Colossus(H100 15万 + H200 5万 + GB200 3万、推定20万基超) |
| GPU計算資源 | 非公開、共有クラウド前提 | 単一コヒーレント・クラスタで数十万基規模 |
| 学習ループ | 事前学習中心、RL後工程は限定的 | 大規模RLポストトレーニング+継続学習(※1) |
| コンテキスト扱い | IDE内補完+リポジトリ限定 | MCP経由でDB・社内ツール・Web全方位 |
| エージェント機能 | Copilot Workspace(プレビュー) | Agent Mode、Background Agent、MCPファーストIDE |
| 想定モデル更新頻度 | 数カ月単位のバージョンアップ | 日次レベルのファインチューン(Colossus前提) |
| 主要ユースケース | 関数補完、チャット、軽いPR | モノレポ全体の自律リファクタリング、自動PR、知識労働全般 |
※1:継続学習=デプロイ後もユーザ挙動・テスト結果から日次でモデルを微調整する運用。Grok 3での「continuous daily improvement」運用がColossusで実証済み。
【図解】技術アーキテクチャ・関係図
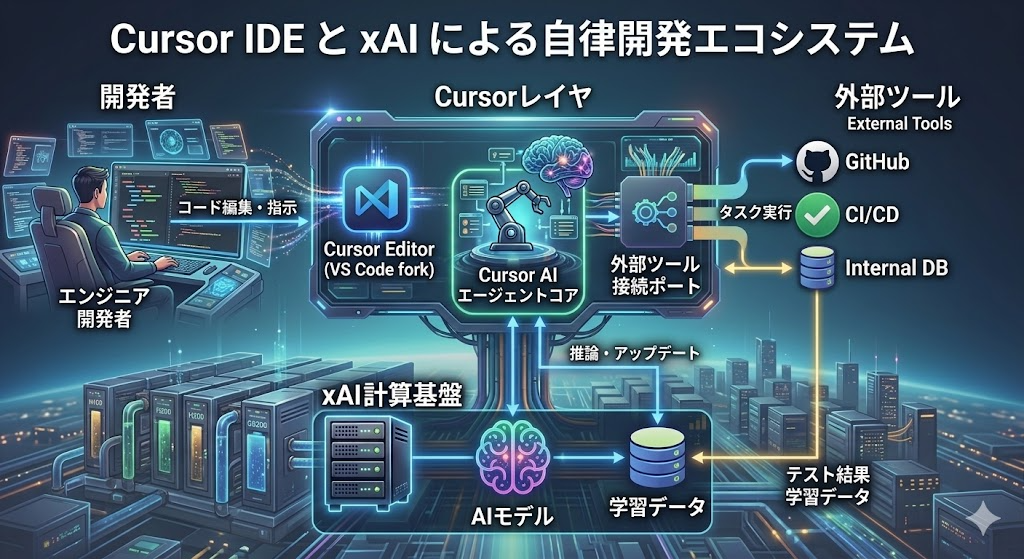
【考察】ITエコシステム・業界へのインパクト
本件は単一のM&Aニュースではなく、AIインフラのパワーバランスを組み替える戦略的な布石として読む必要があります。
1. Microsoft/GitHub Copilotへの非対称な脅威 MSFTはOpenAI経由で強力なコーディング能力を持ちますが、学習インフラはAzureの汎用クラウドと論理共有です。一方、Cursor × Colossusは単一テナント・単一ワークロード向けに最適化された垂直統合です。これはクラウドの時代に専用サーバが一定シェアを保ち続けているのと同じ構造で、特定ドメインでは垂直統合が水平分業より早く回る古典的パターンの再演です。
2. NVIDIAの長期需要は再確認、ただし内訳は変わる Colossusの増強ロードマップ(100万GPU構想)はNVDAにとって依然として最強の追い風ですが、需要の中心はH100からH200/GB200へ急速に移行します。xAIは既にGB200を3万基デプロイ済みで、第2フェーズではGB200を11万基追加する計画で、日本の半導体装置産業・HBM関連銘柄にも波及します。
3. TSMCとHBMサプライチェーンのさらなる逼迫 GB200はCoWoS-L先端パッケージングとHBM3e 8スタックを前提とします。CursorがColossusに乗ることは、事実上もう一つのOpenAI/Anthropic級プレーヤーが先端プロセスのキャパシティを食いに来ることを意味し、2026〜2027年のTSMC先端パッケージ供給逼迫をさらに深刻化させます。
4. 「計算資源 vs プロダクト」の非対称パートナーシップという新型契約 600億ドル買収オプション+100億ドル提携料という構造は、「計算資源を持つ側がプロダクトを後から取り込むコールオプション」と解釈できます。今後、同様のスキーム(計算資源プロバイダが有望SaaSに対してオプション付き提携を結ぶ)が他領域に波及する可能性が高く、SaaSのバリュエーションロジックそのものが変わります。
5. 日本のエンタープライズへの影響 Cursorは既に国内の開発現場で導入が進んでいますが、学習データの流れ先がxAI/SpaceX配下のインフラに寄ることは、データ主権・コンプライアンス面での検討事項を増やします。金融・公共系は特にオンプレ版やデータ境界設定の要求が強まるはずです。
まとめ
本件の本質は「マスクが買う/買わない」ではありません。世界最大級のAI学習クラスタと、開発者に最も浸透したAI IDEが、企業の壁を越えて直結したという事実そのものが、開発者ツール市場の構造を不可逆に動かしています。600億ドルの買収オプションは表層、100億ドルの「共同作業対価」こそが、計算資源をコールオプション化する新しい資本戦略の始まりです。GitHub Copilotが築いた「クラウド × コード補完」の標準型は、これから数年で「専用スーパーコンピュータ × 自律エージェント × MCPエコシステム」という別軸の構造にリプレイスされます。読者のエンジニアが来週以降のIDE選定で頭に入れておくべきは、単一の機能差ではなく、どの計算基盤の恩恵を受けるモデルに自分のコードが食わされるのかという選択の意味です。
引用元記事・補足資料
- SpaceX says it has option to acquire startup Cursor for $60 billion(Reuters / Investing.com):今回のオプション契約を最初期に報じたReuters配信記事。契約の大枠を事実ベースで確認するのに最適。
- SpaceX says it can buy Cursor later this year for $60 billion or pay $10 billion(CNBC):契約構造と「共同作業対価」表現の意味を掘り下げたビジネス報道。
- SpaceX Says It Has Agreement to Acquire Cursor for $60 Billion(Bloomberg):金融面・バリュエーション観点での一次報道。
- xAI to Rent Computing Power to Cursor(The Information):本提携の伏線となった、xAIがCursorにGPUを貸与していたとの事前報道。
- Colossus: The World’s Largest AI Supercomputer(xAI公式):Colossusの仕様・建設速度・1M GPUロードマップに関する一次情報。
- Colossus(Wikipedia):H100/H200/GB200の構成、電源・冷却インフラの詳細を網羅した技術リファレンス。
- xAI Memphis Colossus anatomy(Introl):Spectrum-X採用による95%スループットなど、ネットワーク観点の深掘り解説。
- Introducing the Model Context Protocol(Anthropic公式):MCPの設計思想とN×M統合問題の定式化に関する一次ソース。
- Model Context Protocol Specification:JSON-RPC 2.0ベースのプロトコル仕様書(最新版)。
- Model Context Protocol(Wikipedia):MCPのLinux Foundationへの移管など、エコシステムの最新動向。


コメント