
【エグゼクティブ・サマリー】
- DeepSeekが1.6兆パラメータの新フラッグシップ「V4-Pro」をプレビュー公開し、史上初めてHuawei Ascendに最適化されたフロンティア級モデルが誕生した
- 出力トークン単価は$3.48/Mと、GPT-5.4($30/M)の約9分の1、Claude Opus 4.6($25/M)の約7分の1という攻撃的な価格設定
- 米国務省は同日、DeepSeekらを名指しで「米AIモデルの不正蒸留」を疑う外交公電を世界中の在外公館に発出。技術発表と地政学イベントが完全に同期した
既存テクノロジーの限界と課題
DeepSeek V4の何が凄いのかを語る前に、まず「なぜ今のフロンティアLLMはNvidia GPUなしでは動かせないと言われてきたのか」を整理する必要があります。これはGPUの演算性能だけの話ではありません。
- メモリ容量の壁: 1兆パラメータ級のMoE(※Mixture of Experts、専門家混合モデル。複数の小さなネットワークを切り替えて使う仕組みのこと)を動かすには、最低でも数百GB〜数TB級のVRAMを単一の論理空間として束ねる必要がある
- インターコネクト(※チップ間配線)の壁: 数千個のチップを跨いでパラメータと中間状態を同期させるには、Nvidia独自のNVLink/NVSwitch級の超低遅延ファブリックが事実上必須だった
- ソフトウェアスタックの壁: PyTorchやvLLMといった主要な学習・推論フレームワークはCUDAエコシステムに深く依存しており、別アーキテクチャへの移植コストは膨大
- 輸出規制の壁: 米国の対中規制でNvidia H100/H200/Blackwellは中国向けに出荷できず、譲歩版のH800ですら2025年以降は実質的に締め付けが強化されている
つまり中国のAI企業は「どんなに金を払っても最先端GPUを買えない」状況に追い込まれていた。これがDeepSeek V3までの世界観です。「ハードがなければモデルは育たない」——この常識を、DeepSeekは今回ひっくり返しに来ました。
ニュースの核心
DeepSeekは金曜日(2026年4月24日)、1.6兆パラメータと100万トークンのコンテキストウィンドウを持つV4のプレビューをリリースし、これは同社にとって最強のモデルであり、Nvidiaではなく Huawei Ascend AIプロセッサ向けに最適化された初の主要なフロンティアリリースとなった。同じ日に米国務省が外交公電でDeepSeekらの知財窃盗疑惑を世界に通知したことで、技術発表は完全に外交カードと一体化しました。
ここで重要なのは、DeepSeek V4が単に「中国チップで動いた」というだけでなく、モデル設計そのものが推論コストを劇的に圧縮するアーキテクチャ革命を伴っている点です。
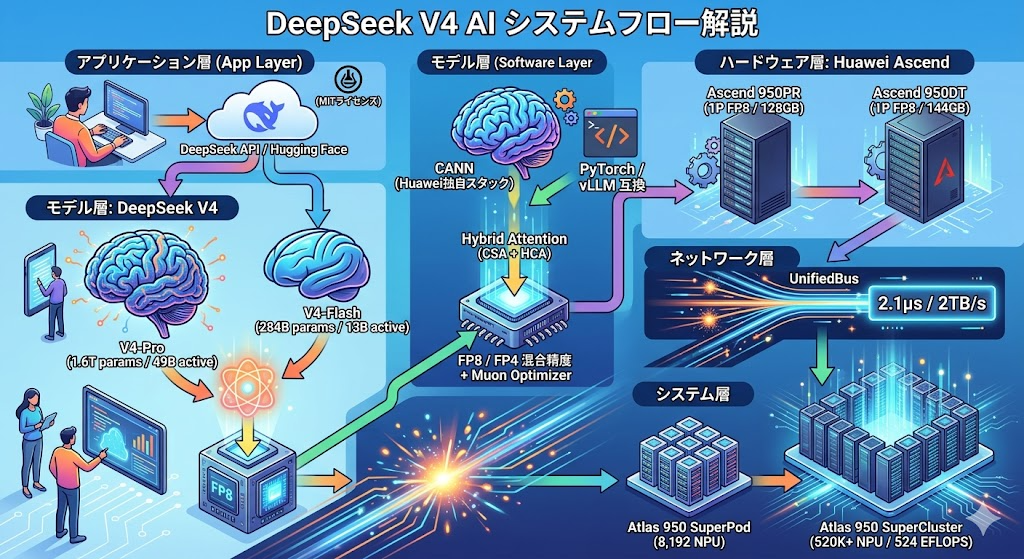
モデル構成: 大胆な「2階建て」戦略
V4は2つのバリアントで構成されています。
- V4-Pro: 1.6兆パラメータ、49B活性化(MoE)、コンテキスト1M、入力$1.74/M・出力$3.48/M
- V4-Flash: 284Bパラメータ、13B活性化(MoE)、コンテキスト1M、入力$0.14/M・出力$0.28/M
V4-Proは33兆トークンで学習されており、DeepSeekの主張を信じるなら、すべてのオープンウェイトLLMを上回り、ベンチマークスイート全体で西側の最良のプロプライエタリモデルに匹敵するとされています。
たとえ話で理解する「MoEとアテンション圧縮」
ここが初心者には一番難しい部分なので、「巨大なロイヤルキッチン」にたとえます。
従来のDenseモデル(GPT-3型)は、注文が1つ来るたびにフランス料理人も寿司職人もパティシエも、店の全シェフ全員が一斉に動くような構造でした。コストが膨大です。
MoEは、「注文の内容を見て、必要な専門シェフだけを呼び出す」仕組みです。V4-Proの場合、1.6兆人のシェフが控えていますが、1つの問いに対してはわずか49Bだけが動く。これだけで推論コストが数十分の一になります。
さらにV4はCompressed Sparse AttentionとHeavy Compressed Attentionを組み合わせたハイブリッドアテンション機構を導入し、推論時に必要な計算量を削減し、モデル状態を追跡するために使用されるキーバリューキャッシュを圧縮する新機構を導入しました。これは「シェフが過去の注文メモを全部広げるのではなく、要点だけ書いた付箋を見る」ような仕組みで、1Mトークンの長文を扱ってもメモリ消費が爆発しないようになっています。
加えて、重みはFP8/FP4混合精度(※従来の半分以下のビット数で数値を保持する方式)で量子化対応学習され、Muonという新オプティマイザで収束速度と学習安定性を高めています。FP4の採用は、メモリ帯域とフットプリントを物理的に半減させる「コスト破壊の実弾」です。
Huawei Ascend 950への「接続」が意味するもの
DeepSeek V3はNvidia H800 GPUを2,048枚使って学習されましたが、V4はHuaweiのAscend NPUプラットフォーム上でEP(Expert Parallel)スキームの検証が完了しています。これはモデルがHuaweiハードウェア上で完全に学習されたことを意味するわけではなく、DeepSeekが推論用にAscendを検証したことを意味するのですが、それでも意味は重い。
Huaweiが用意したインフラ側の主役はAtlas 950 SuperPodです。スペックを見ると、その異常さがわかります。
- Ascend 950DT 1チップ: 1 PFLOPS(FP8)/2 PFLOPS(FP4)、メモリ144GB、メモリ帯域4 TB/s
- Atlas 950 SuperPod: 8,192個のNPUを1つの論理計算機として束ねる
- UnifiedBusインターコネクト: 2.1µsの低遅延、2 TB/sのチップ間帯域
- Atlas 950 SuperCluster: 64個のSuperPodを連結、合計52万NPU超、524 EFLOPS(FP8)
ここでまたたとえ話を入れます。Nvidiaの最新世代「NVL72」はラック1本(72 GPU)を高速バス(NVLink)で結ぶ構造で、いわば「1台の超高級スポーツカー」。一方Huaweiの戦略は「100台の軽自動車を、信号も渋滞もない専用高速道路で並走させて、まるで1台の巨大トレーラーのように振る舞わせる」というもの。個々のチップ性能ではNvidiaに劣ることをHuaweiは公式に認めていますが、「物量と配線」で殴り返す戦略です。
DeepSeek V4-Proはこの巨大トレーラーの上で初めて本格的に走るフロンティアモデル、というわけです。
【比較表】従来アーキテクチャとのスペック比較
| 項目 | DeepSeek V3 (旧) | DeepSeek V4-Pro (新) | OpenAI GPT-5.4 | Anthropic Claude Opus 4.6 |
|---|---|---|---|---|
| 総パラメータ | 671B | 1.6T | 非公開 | 非公開 |
| 活性化パラメータ | 37B | 49B | 非公開 | 非公開 |
| コンテキスト長 | 128K | 1M | 数百K級 | 数百K級 |
| 主要学習ハードウェア | Nvidia H800 ×2,048 | Ascend NPU検証済 | Nvidia系 | Nvidia/独自系 |
| 出力トークン単価 | $1.10/M | $3.48/M | $30/M | $25/M |
| 数値精度 | FP8 | FP8 + FP4 混合 | 非公開 | 非公開 |
| アテンション機構 | MLA | Hybrid (CSA+HCA) | 非公開 | 非公開 |
| ライセンス | MIT | MIT (オープン) | クローズド | クローズド |
注: V4-Proの単価は同等性能帯のクローズドモデルと比較して約1/7〜1/9に位置する一方、開発時期では「3〜6ヶ月遅れ」と自社で認める水準。価格レバーを最大限に引いて市場シェアを取りに来た構図です。
【図解】技術アーキテクチャ・関係図
【考察】ITエコシステム・業界へのインパクト
ここからはエンジニア視点での構造分析です。短期的・中期的に効いてくる変化を整理します。
- Nvidiaの「中国市場ロックイン」が事実上崩れる: 学習はまだNvidia依存の可能性が残るものの、推論サービングがAscendで成立することの意味は重い。1兆パラメータ級モデルの推論はGPUの最大消費領域であり、ここをHuaweiに奪われるとNVDAのTAM(獲得可能市場)が中国分まるごと縮む
- 「価格×オープンウェイト」の二重圧力: クローズド勢(OpenAI/Anthropic)は付加価値の再定義を迫られる。API料金で勝負する時代は終わり、エージェント機能・セキュリティ・SLA・コンプライアンスといった「周辺価値」で稼ぐ構造に移行せざるを得ない
- 国内データセンターのアーキテクチャ選定が複雑化: 日本の事業者にとっても「H200のクラスタを発注する」のか「Ascend搭載クラウドを借りる」のか、地政学・コスト・性能の三軸で意思決定の難易度が跳ね上がる
- 「蒸留」が国際政治の新キーワード化: OSTPメモはAnthropicの2026年2月の開示——DeepSeek、Moonshot AI、MiniMaxの3つの中国研究所が約24,000の不正アカウントと1,600万件超のやり取りでClaudeモデルに対する抽出キャンペーンを実行したという報告——を直接の根拠としている。今後はAPI利用規約・レート制限・モデル出力ライセンスが、各社の知財防衛の最前線になる
- オープンソースAIの定義が揺らぐ: V4はMITライセンスでHugging Faceに重みごと公開されている。これを「無断蒸留の成果物だ」と見る視点と、「人類共有のコモンズだ」と見る視点が、規制の現場で正面衝突する
まとめ
DeepSeek V4のリリースが示しているのは、「規制で抑え込む」というアプローチが、結果的に中国のフルスタック内製化(チップ・インターコネクト・モデル・ライセンス)を加速させたという、輸出管理の構造的なアイロニーです。米国務省の外交公電と同じ日にHuaweiチップで動く1.6兆パラメータモデルが出てきたのは偶然ではなく、「規制のたびに中国は階段を1段上る」という2024年以降の繰り返しパターンの最新形に過ぎません。
技術側の論点は明快です。1チップの絶対性能ではNvidiaが勝ち続ける一方、システム全体の物量とインターコネクトでHuaweiが追いついてきた。そしてDeepSeekは、このハードの性質に合わせてモデル側のアテンションと精度を作り変えた。ハードとソフトを共設計(co-design)できる組織が勝つ——これがV4が突き付けた、たぶん一番冷たい事実です。
5月14日に予定されているTrump-Xi北京会談で、半導体輸出規制とIP紛争の双方が議題になる以上、次の数週間は「政治の言葉でテック業界が動かされる期間」になります。自社のスタックがどちらの陣営のチップ・モデル・ライセンスに依存しているかを、いま棚卸ししておく価値があります。
引用元記事・補足資料
DeepSeek launches 1.6 trillion parameter V4 on Huawei chips as U.S. escalates AI theft accusations (Tom’s Hardware):DeepSeek V4の概要・価格・米中対立を一本で俯瞰した元記事。
DeepSeek’s new models offer big inference cost savings (The Register):V4のアーキテクチャ詳細、Nvidia/Ascend両対応の技術的解説。
DeepSeek Releases V4 Models With 9.5x Lower Memory Requirements (gHacks):Hybrid Attention・FP4・Muon Optimizerなど新機構の解説。
DeepSeek unveils V4 model, with rock-bottom prices and close integration with Huawei’s chips (Fortune):価格戦略と中国AIエコシステムの市場インパクト分析。
DeepSeek unveils next-gen AI model as Huawei vows ‘full support’ (SCMP):Huawei側の対応と中国国内テック業界の受け止め。
Huawei Ascend NPU roadmap examined (Tom’s Hardware):Ascend 950/960/970のスペックとUnifiedBusの技術詳細。
Huawei Launches Open-Access SuperPoD Architecture (Huawei Official):Atlas 950 SuperPodとUnifiedBusの一次情報(Huawei公式)。
U.S. State Department orders global warning about alleged China AI thefts (CNBC):米国務省外交公電のRoyterによるスクープ報道。
White House accuses China of ‘deliberate, industrial-scale campaigns’ (Nextgov/FCW):4月23日付OSTPメモNSTM-4の解説。
White House Memo Targets ‘Adversarial Distillation’ of U.S. AI Models (NYU Shanghai RITS):Anthropicの2026年2月開示(24,000アカウント・1,600万件)の内訳を含む詳細分析。


コメント