
【エグゼクティブ・サマリー】
- AnthropicがBroadcom経由で2027年から3.5GW規模のGoogle TPUキャパシティを確保。2026年稼働予定の1GWと合算し、合計4.5GW超の専用AIコンピュートを手中に収める
- Anthropicの年換算収益(ARR)は300億ドルを突破し、2025年末の約90億ドルから約3.3倍という急激な成長を記録
- BroadcomはAnthropicとOpenAIという米国フロンティアモデル企業上位2社のカスタムシリコン実装を独占し、AI半導体エコシステムの「インビジブル・レイヤー」として君臨する構造が確定しつつある
既存テクノロジーの限界と課題
大規模言語モデル(LLM)の推論・学習ワークロードがギガワット級に拡大する中、汎用GPUアーキテクチャのままでは解決困難な物理的・経済的なボトルネックが複数存在する。
- 電力密度の壁: 汎用GPU(例:NVIDIA H100/B200)はゲームや科学計算など多様なワークロードに対応するため、ダイ面積と電力消費の多くを汎用演算ユニットに割いている。LLM推論の中核であるmatrix multiply-accumulate(MMA)演算に特化した設計ではないため、ワット当たりのトークン生成効率(tokens/Joule)が構造的に低い
- 帯域幅のミスマッチ: トランスフォーマーモデルのAttentionメカニズムはメモリ帯域幅にボトルネックが生じやすい(Arithmetic Intensity が低い)。HBMを搭載したGPUでも、モデルが数千億パラメータ規模になるとチップ間のNVLink/NVSwitch帯域がネックになる
- TCO(総所有コスト)の爆発: ギガワット級のデータセンターにNVIDIA GPUを詰め込む場合、ライセンス料・冷却コスト・ラックスペース費用の合算は、専用ASICと比べて数倍に膨らむ。Anthropicが支出する3.5GW分のコンピュートを汎用GPUで賄った場合、サービス原価率の大幅な悪化は避けられない
- ソフトウェアスタックの分断: 複数クラウドに散在するGPUクラスタは、分散学習・推論においてネットワーク遅延とジョブスケジューリングの複雑性を増大させる。Googleのようにハードウェア・ソフトウェア・ネットワークを垂直統合した専用スタックが、大規模ワークロードでは圧倒的に有利
ニュースの核心とアーキテクチャの優位性
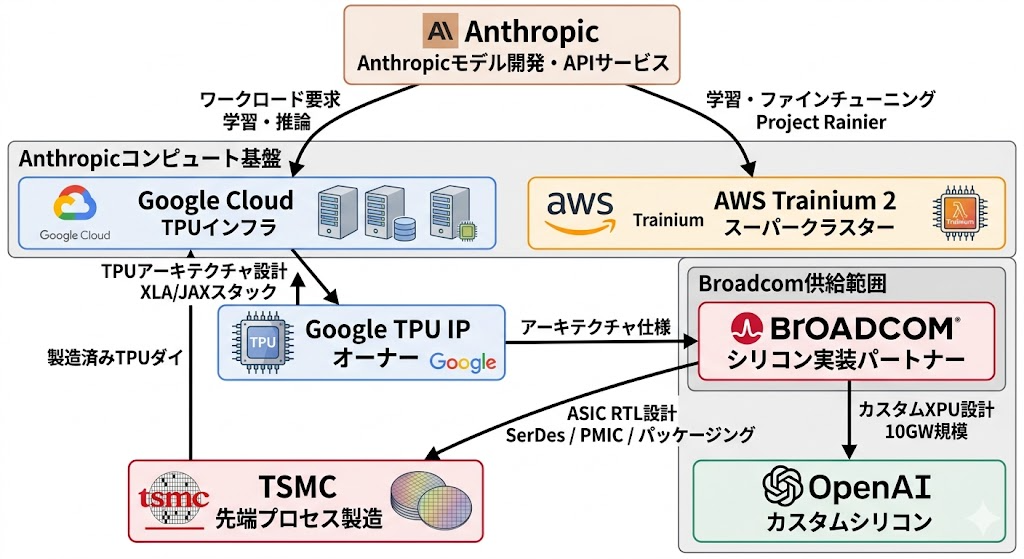
今回の契約構造は、単なる「大型調達ニュース」ではなく、AIコンピュートサプライチェーンの垂直統合と役割分担が確定したことを意味する。SEC提出書類(Form 8-K)の開示内容から、二つのリンクされた取り決めが明らかになっている。
① サプライ・アシュアランス契約(〜2031年)
Broadcomは、Googleの次世代AIラック向けにネットワーキングコンポーネントおよびその他のコンポーネントを2031年まで供給することをコミット。具体的には以下が含まれると推測される。
- 高速SerDes(Serializer/Deserializer)IP: チップ間・ラック間の超高速シリアル通信を担うアナログ回路ブロック。TPUクラスタのスケールアウトには不可欠
- 電力管理IC(PMIC): ギガワット級ラックの電力変換・分配の効率を左右するコンポーネント
- 先進パッケージング技術: HBM統合やチップレット構成に対応するインターポーザー技術
② Anthropic向け三者間コラボレーション(2027年〜)
構造的に興味深いのは、GoogleがTPUアーキテクチャとソフトウェアスタック(XLAコンパイラ、JAXエコシステム)を所有し、Broadcomがシリコン実装(RTL→テープアウト)を担い、TSMCが製造を行うという分業モデルだ。
“Google, of course, owns both the TPU architecture and software stack, with Broadcom acting as the silicon implementation partner, converting Google’s architecture into a manufacturable ASIC layout while supplying high-speed SerDes, power management, and packaging. TSMC handles fabrication.” — Tom’s Hardware, 2026年4月7日
この構造において、Broadcomの競争優位はIPそのものではなく、「アーキテクチャを量産可能なASICレイアウトに変換し、ネットワーク・電源コンポーネントまで一括供給できる実装力」にある。
AnthropicがAWSのProject Rainier(Trainium 2ベースのスーパークラスター)に加えて本契約を締結した理由も明確だ。単一クラウドへの依存を避けつつ、学習にはAWS/Trainium 2、推論サービングにはGoogle TPUというワークロード特性に最適化したマルチクラウド戦略を取ることで、レイテンシとコストを最適化する意図が透けて見える。
Mizuhoアナリストのリポートによれば、Broadcomのアントロピック関連AI収益は2026年に210億ドル、2027年には420億ドルに達すると推計されており、これは単一顧客からの収益としては半導体業界史上最大規模のひとつとなりえる。
【比較表】従来アーキテクチャとのスペック比較
| 項目 | 汎用GPU(NVIDIA B200相当) | Google TPU v6(Trillium)世代 |
|---|---|---|
| 主なターゲット | 汎用HPC・AI・グラフィックス | Transformerモデルの学習・推論特化 |
| 電力効率(tokens/W) | 相対的に低い(汎用設計のオーバーヘッド) | 高い(MMA演算に特化したデータフロー) |
| チップ間インターコネクト | NVLink / NVSwitch(プロプライエタリ) | ICI(Inter-Chip Interconnect)、高密度トーラストポロジー |
| ソフトウェアスタック | CUDA / cuDNN(NVIDIAエコシステム) | XLA / JAX(Google独自、Anthropic Claudeはここで最適化) |
| スケールアウト単位 | DGX SuperPOD(数千GPU) | TPUポッド(数千〜数万チップ) |
| 供給モデル | クラウド経由 or 直販 | Broadcom実装→Google Cloud経由(Anthropic専有枠) |
| コンピュートコミット規模 | スポット〜数百MWオーダー | 2027年〜 3.5GW(Anthropic専有) |
| 主なユースケース | 汎用学習・ファインチューニング・推論 | Claude大規模推論サービング・基盤モデル学習 |
【図解】技術アーキテクチャ・関係図
【考察】ITエコシステム・業界へのインパクト
① カスタムASICシフトの不可逆性
Anthropicの3.5GW確保は、AIワークロードが「汎用クラウドGPUを必要なだけ借りる」フェーズを完全に卒業したことを示す。年換算300億ドルの収益を持つAIサービス企業がギガワット級のコンピュートを長期コミットメントで確保するモデルは、従来の電力会社やハイパースケーラーに近い「インフラ企業」的な資本配置だ。
② Broadcomの「インビジブル・インフラ」戦略の完成
Broadcomは現在、AnthropicとOpenAIという米国フロンティアAIの上位2社のカスタムシリコン実装を担っている。どちらのモデルが市場を制しても、実装レイヤーとしてBroadcomは収益を得る構造だ。これはかつてIntelが「PCメーカー間の競争に関係なくIntelが勝つ」という構造を確立したことと本質的に同じロジックである。
投資銀行Mizuhoの推計(Vijay Rakesh アナリスト)では、Broadcomのアントロピック関連AI収益は2027年に420億ドルに達する見通しであり、これはBroadcom全体の現在の年間売上高に匹敵するオーダーだ。
③ NVIDIAへの影響——即座の崩壊ではなく、構造的な侵食
注目すべきは、AnthropicもOpenAIも引き続きNVIDIA GPUをAWS・Google Cloud・Azureを通じて多用している点だ(記事本文に明記)。TPUやカスタムASICへのシフトは、NVIDIAの全面代替ではなく「超大規模・繰り返し推論」という特定ユースケースからの侵食だ。一方でOpenAIはAMD GPUへの6GWコミットも行っており、NVIDIAへのヘッジが業界全体で進行中であることも見落とせない。
④ TSMCの製造依存度と地政学リスク
Google TPUの製造はTSMCが担う。BroadcomのASIC実装もTSMCのN3/N2プロセスへの依存が高い。AnthropicのSEC開示では「インフラの大部分は米国内に設置される」と明記されており、これはCHIPS法に基づく補助金受給要件や、対中輸出規制の観点からの地政学的リスクヘッジと整合する。ただし、最先端プロセスのファウンドリ能力が実質的にTSMC台湾拠点に集中している現状は、4.5GW規模のコンピュートサプライチェーン全体の単一障害点(SPOF)として残存し続ける。
⑤ 日本のクラウド・インフラエンジニアへの実務的示唆
- CUDAエコシステムへの依存度の棚卸し: 自社AIワークロードがTPUやAMD ROCmへの移行を将来的に検討する場合、XLAやOpenXLAへの対応コストを今から評価しておく価値がある
- 電力・冷却設計の見直し: ギガワット級施設が前提になる時代の冷却アーキテクチャ(液冷・浸漬冷却)は、日本国内の次世代DC設計においても避けられないテーマ
- マルチクラウド前提のMLOpsパイプライン: AnthropicがAWS(Trainium)とGoogle(TPU)を同時並行で使う構成は、異種アクセラレーター間でのモデルポータビリティを確保するツールチェーン(JaxやOpenXLA準拠のコンパイラ)の重要性を示している
まとめ
Anthropicの3.5GWコンピュートコミットメントが示すのは、AIサービスが「ソフトウェア産業」から「エネルギー集約型の物理インフラ産業」へと完全に転換したという事実だ。年300億ドルの収益企業が、インフラコストとして電力会社並みの長期・大規模コミットを行う——これはSaaSのユニットエコノミクスとは根本的に異なる事業構造である。
Broadcomが二大フロンティアモデル企業の実装レイヤーを独占する構造は、「半導体設計の民主化(ファブレス化)」の次のステージとして、超特化型ASIC実装能力こそが競争の護城河になるという命題を証明しつつある。この構造が固まるほど、TSMC・ASML・先端パッケージング企業といったバリューチェーン上流の重要性も比例して増大する。
引用元記事・補足資料
Broadcom to supply Anthropic with 3.5 gigawatts of Google TPU capacity from 2027 — Tom’s Hardware:本記事の主要な事実の根拠となるTom’s Hardwareによる一次報道。契約の全体構造・Anthropic CFOコメント・OpenAIとの比較を網羅。
Broadcom Inc. SEC Filing (Form 8-K) — U.S. Securities and Exchange Commission:2027年からの3.5GWキャパシティ供給契約および2031年までのGoogle TPU供給コミットメントの法的根拠となる一次情報。
Expanding our partnership with Google and Broadcom for multiple gigawatts of next-generation compute — Anthropic Official Blog:AnthropicのARR300億ドル突破・法人顧客1,000社超・インフラ戦略に関するCFO Krishna Raoのコメントを含む公式声明。
Broadcom and Google Benefit Mightily from Anthropic’s Meteoric Growth — The Next Platform:Mizuho証券アナリスト(Vijay Rakesh)によるBroadcomのAnthropic関連AI収益推計(2026年210億ドル・2027年420億ドル)の参照元。TPUコストの$/GW試算など財務的考察も詳細。
Broadcom agrees to expanded chip deals with Google, Anthropic — CNBC:BroadcomのCEO Hock Tan発言(「2026年は好調なスタート」)およびMizuho推計の数値を直接引用した信頼性の高い報道。OpenAIのAMD 6GWコミットにも言及。
Anthropic ups compute deal with Google and Broadcom amid skyrocketing demand — TechCrunch:TechCrunchによる詳細報道。3.5GWという具体数値がBroadcomのSEC提出書類由来であることを明記しており、Anthropic公式発表との差分を整理する上で有用

コメント