
【エグゼクティブ・サマリー】 Armが創業35年にして初めて自社ブランドの完成シリコン「AGI CPU」を発売。TSMCの3nmプロセスに136個のNeoverse V3コアを集積し、MetaやOpenAIをリードパートナーとして据えた本チップは、単なる製品追加を超えた同社のビジネスモデルの構造転換を意味する。エージェンティックAI時代に求められる「CPUによるオーケストレーション」という新需要を取り込み、GPUの陰に隠れてきたサーバーCPU市場で一気にゲームチェンジャーを狙う。
既存テクノロジーの限界と課題
大規模AIシステムにおける「CPUのボトルネック」は、GPUアクセラレータの爆発的な普及とともに急速に可視化されてきた。従来の汎用x86サーバーCPUは、推論や学習タスクの演算自体をGPUにオフロードする構成が主流だが、その前後の処理——複数モデル間のデータオーケストレーション、メモリプール管理、I/Oルーティング——はCPU側が担う。
問題はここにある。チャット型の静的AIと比べ、エージェンティックAI(複数のAIエージェントが自律的に推論・タスク実行を繰り返すシステム)では、このオーケストレーション負荷が桁違いに増大する。10エージェントが並行稼働するだけで、コンテキスト切り替え・メモリ移動・加速器間通信の頻度は従来比で数十倍になり得る。
旧世代のアーキテクチャが抱える具体的な限界は以下の通りだ。
メモリ帯域の壁: DDR4世代のメモリコントローラは6〜8ch構成が多く、帯域幅は250〜350 GB/s程度に留まる。AGIワークロードでは単一CPUソケットのメモリ帯域が常時飽和し、GPUへのデータ供給が律速となる現象が頻発している。
I/O帯域の壁: PCIe Gen4世代(最大64 GB/s)では、NVLink規模のGPU間通信と並行してCXL拡張メモリや高速NICを同時駆動すると、PCIeスイッチのトポロジーが即座にボトルネックになる。
電力密度とスケーラビリティの壁: x86プラットフォームは複雑な命令セットデコードやレガシー互換レイヤーが常に消費電力を押し上げる。AIワークロードに最適化されていないマイクロアーキテクチャのまま高クロック化するアプローチは、W/性能比の観点で限界に達しつつある。
ニュースの核心とアーキテクチャの優位性
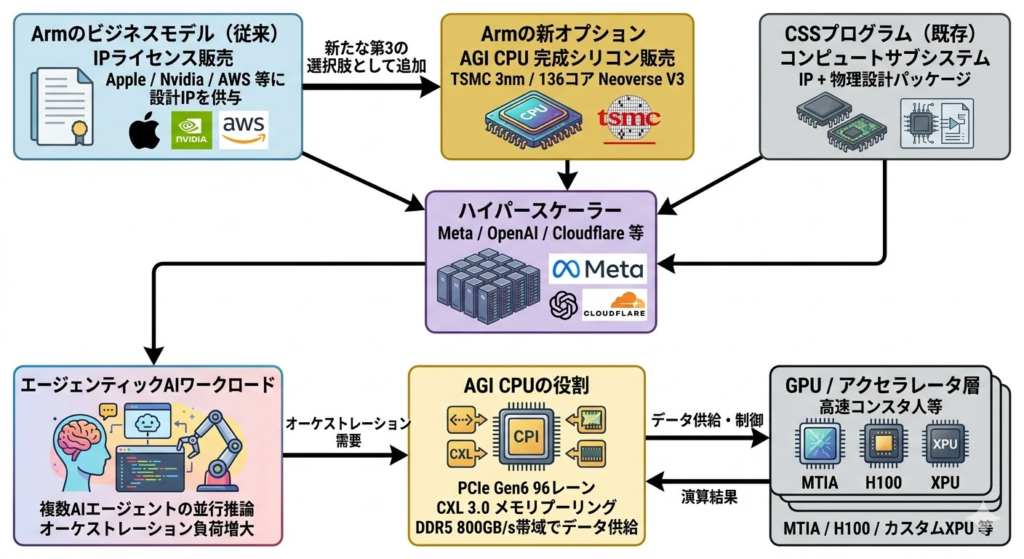
Tom’s Hardwareの2026年3月24日付報道によれば、Armは自社設計・販売の完成品シリコン「AGI CPU」を正式発表した。これは同社の35年の歴史において初の試みとなる。
チップの主要スペックは以下のとおりだ。
- プロセス:TSMC 3nm(N3)
- コア数:最大136コア(Neoverse V3)、2ダイ構成
- 動作周波数:全コアブースト3.2 GHz、最大3.7 GHz
- TDP:300W
- メモリ:DDR5×12ch(最大8800 MT/s)、総帯域800 GB/s超、コアあたり6 GB/s、ターゲットレイテンシ100ns以下
- I/O:PCIe Gen6×96レーン、CXL 3.0ネイティブ対応
Armは自社の参照プラットフォームをOpen Compute Project(OCP)のDC-MHS規格準拠の10U dual-nodeサーバーとして設計。標準的なエアクール36kWラックに30ブレード(60チップ)を搭載でき、合計8,160コアを収容する。さらにSupermicroと共同で液冷200kW構成を提供予定で、この場合336チップ・45,000コア超のラックが実現する。
Armはx86比で「ラックあたり性能2倍以上」と主張しているが、同報道でも断られているように、この数値は現時点で独立ベンチマークではなく同社内部試算によるものである点は留意が必要だ。
MetaのインフラトップであるSantosh Janardhan氏は、同社が自社カスタムアクセラレータ「MTIA」と組み合わせてAGI CPUを展開する計画を明らかにしており、複数世代にわたるロードマップへのコミットメントを表明している。またOpenAIのSachin Katti氏(産業コンピューティング担当)は以下のように語った。
AGI CPUは、大規模AIワークロードを調整するオーケストレーションレイヤーを強化することで、OpenAIのインフラにおいて重要な役割を果たすことになる。
商用パートナーとしては、Meta・OpenAI以外にもCerebras、Cloudflare、F5、Positron、Rebellions、SAP、SK Telecomが名を連ねる。
【図解】技術アーキテクチャ・関係図
【エンジニア視点】ITエコシステム・業界へのインパクト
PCIe Gen6とCXL 3.0の同時採用が意味するもの
今回の仕様で特に注目すべきは、PCIe Gen6(96レーン)とCXL 3.0のネイティブ対応を単一SoCで実現している点だ。PCIe Gen6は理論転送速度がGen5の2倍となる最大256 GB/sのx16帯域を提供し、NVIDIAのGrace Hopperに代表されるNVLink構成ではなくオープンスタンダードで同等クラスのGPU-CPU間帯域を達成できる可能性がある。
さらにCXL 3.0は単なるメモリ拡張にとどまらず、メモリプーリング(複数ホストが物理DRAMを共有)とメモリファブリック(数百ノードにまたがるコヒーレントなメモリ空間)を実装できる。エージェンティックAIでは大規模なKVキャッシュ(各エージェントの会話履歴や中間ステート)をメモリ上に保持し続ける必要があるが、CXL 3.0ファブリックがあればその容量をラック外に透過的に拡張できる。DDR5×12chで800 GB/s超という帯域はその入口に過ぎない——本質的な価値はCXL 3.0によるスケールアウト能力にある。
IPライセンサーのシリコン参入が持つ二重の意味
Armのビジネスモデル転換は業界再編に直結する。これまでArmは設計IP(命令セットアーキテクチャ+コアRTL)を販売し、製造・調達リスクを一切負わないアセットライト経営の代表例だった。今回の完成シリコン販売は、その原則を破る決断だ。
一方でArmは「既存ライセンシーと競合するわけではない」と強調している。確かにAppleのM4シリーズ、NVIDIAのGrace、AWSのGraviton、GoogleのAxion、MicrosoftのCobaltは、それぞれ各社の差別化戦略を反映したカスタムシリコンであり、AGI CPUが直ちに代替するものではない。しかしArmが同じデータセンターに「完成品」を持ち込んだ事実は、将来世代でのロードマップ統合・機能制限・優先設計リソースの配分をめぐるライセンシーとの交渉力構造を確実に変える。
データセンターアーキテクチャへの波及
現在主流のScale-Up型GPU クラスター(NVLinkメッシュ内に数百〜数千GPU)に対し、AGI CPUが描くのはScale-Out型CPU主導のオーケストレーション層だ。200kWラックあたり45,000コアという数字は、推論エージェントのスレッドをCPU側で密に詰め込み、必要なときだけGPUに演算をバーストオフロードするアーキテクチャを示唆する。
これはBroadcomが推進するカスタムXPU(特定用途加速器)との親和性も高い——AgenticなプランニングループはCPUで、実際のテンソル演算はカスタムXPUで、という役割分担が現実的な設計指針として浮上してくる。従来の「GPU頂点・CPU裾野」というヒエラルキーは崩れ、CPUとGPU/XPUが対等なピアとして協調するファブリック型データセンターへの移行が加速するだろう。
OCP DC-MHS準拠という選択の戦略性
参照プラットフォームにOCP DC-MHSを採用したことは、既存のハイパースケーラー向けラックラインアップとの互換性を意識した極めて計算された判断だ。MetaはOCPの主要推進者であり、同規格準拠のシェルフをすでに大量展開している。AGI CPUの導入がハードウェアリプレースではなくブレード差し替えで完了するなら、採用のハードルは劇的に下がる。
まとめ
ArmのAGI CPU発表は、半導体業界に複数の地殻変動を同時に引き起こす可能性を秘めている。IPライセンサーとしての立場を守りつつも完成シリコン販売に踏み切った背景には、エージェンティックAI時代に高まる「強力なCPUによるオーケストレーション需要」を自社で直接取り込む戦略的意図がある。
136コア・PCIe Gen6・CXL 3.0という仕様は、現世代のx86プラットフォームが抱えるメモリ帯域・I/O帯域・電力効率の構造的限界を正面から突くものだ。MetaとOpenAIという業界の両横綱をリードパートナーに据え、OCP準拠の参照プラットフォームを揃えたことで、商用展開への道筋はある程度見えている。
ただし、独立ベンチマークの不在、既存ライセンシーとの長期的な緊張関係、そしてNVIDIA Graceやカスタムシリコン各社との実運用上の競合をどう管理するか——これらはArmが向こう数世代のロードマップで解答を示さなければならない課題だ。エンジニアリングコミュニティとしては、CXL 3.0ファブリックとの統合実績、実負荷下でのメモリレイテンシ特性、そして独立機関によるベンチマーク結果を注視すべき局面にある。


コメント