
エグゼクティブ・サマリー
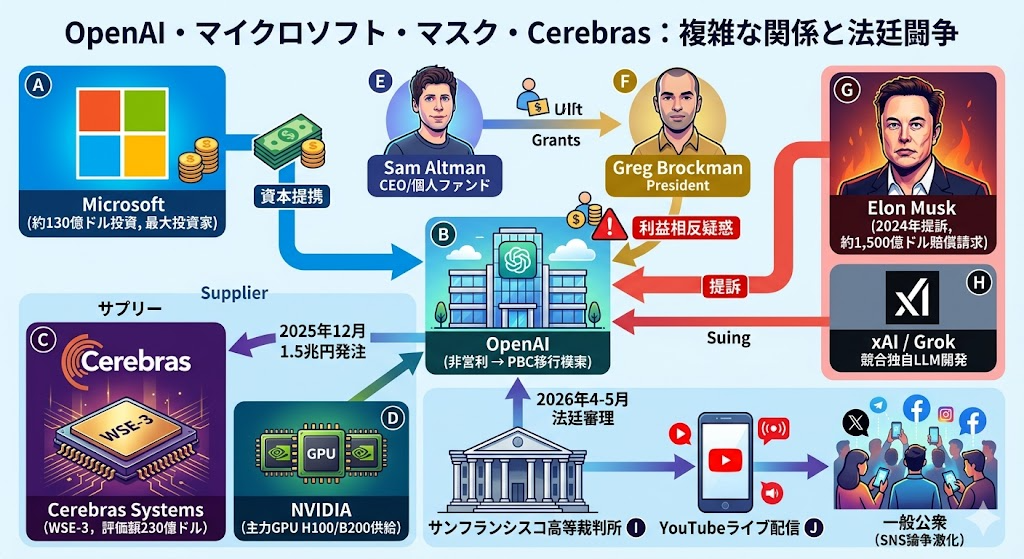
- OpenAIが2025年12月にCerebras社と1兆円規模のチップ調達契約を結んでおり、共同創業者ブロックマン氏の個人投資が利益相反として法廷で暴露された
- この契約はNVIDIAのGPUクラスタが抱えるメモリ帯域とチップ間通信のボトルネックを回避する「ウェハースケール」アーキテクチャへの構造的シフトを意味する
- 訴訟の結果次第ではOpenAIの公共利益法人(PBC)化が差し戻され、Microsoftとの提携構造、そしてAI業界全体の調達戦略が再編される
既存テクノロジーの限界と課題
ここまで生成AIの拡大を支えてきたのは、NVIDIAのGPU(※グラフィックス処理用の高並列演算チップ)を数千枚から数万枚束ねた巨大クラスタです。しかし、このアプローチは物理的な壁にぶつかりつつあります。
ボトルネックは大きく3つあります。
- メモリ帯域の枯渇:LLMのパラメータが数兆規模に膨張する中、HBM(※高帯域メモリ)の容量と帯域が学習速度の上限を決めてしまう
- チップ間通信のレイテンシ:NVLinkやInfiniBandで結ばれたGPU同士のデータ交換に、計算時間の半分近くが食われるケースもある
- 電力と冷却の物理限界:1ラック数十kWの発熱を液冷で処理しなければならず、データセンターの新設地が水資源と電力網に縛られる
これは、片側1車線の高速道路に物流トラックを無理やり詰め込んでいる状態に近い構図です。トラック1台(GPU1枚)の性能をいくら上げても、合流地点(NVLink)で渋滞が発生すれば、全体スループットは頭打ちになります。
OpenAIやAnthropicが直面しているのは、まさにこの「合流渋滞」の問題です。GPT級モデルの次世代学習では、1ジョブで数万GPUを96時間以上稼働させる必要があり、ノード間通信のオーバーヘッドが学習コストを直撃しています。
ニュースの核心
サンフランシスコ高等裁判所で進行中のマスク氏 対 OpenAI 裁判は、表向きは「AIの公共性をめぐる思想闘争」ですが、その水面下ではAI半導体サプライチェーンの構造そのものが法廷で解剖されています。
最大の論点は、共同創業者グレッグ・ブロックマン氏の財務開示書類に登場するCerebras、Stripe、CoreWeave、Helionの4社です。いずれもOpenAIと取引関係にあり、特にCerebrasに関しては、ブロックマン氏が個人投資家として保有していました。
OpenAI did a December 2025 deal with Cerebras, for $10 billion of chips — and Brockman had an investment. The deal increased Cerebras’s valuation to $23 billion. “Your equity in Cerebras became more valuable because of the transaction OpenAI did?” Brockman admits that’s possible.
――The Verge法廷ライブブログ(2026年5月4日)
OpenAIが2025年12月にCerebrasから100億ドル(約1.5兆円)分のチップを発注し、その結果Cerebrasの企業評価額が230億ドルへ跳ね上がった。そしてその恩恵を、発注を承認する側にいた経営幹部が個人として受け取った――これが法廷で本人の口から認められた事実です。
技術的に重要なのは、Cerebrasが提供しているのがウェハースケール・エンジン(WSE)(※シリコンウェハー1枚を切り分けず、まるごと1個のチップとして使う巨大プロセッサ)である点です。
通常のチップ製造では、円盤状のシリコンウェハーをクッキー型で抜くように数百個の小さなダイ(※チップの最小単位)に切り分け、それぞれをパッケージングします。Cerebrasはこの「クッキーの切り分け」を放棄し、ウェハー全体を1つの巨大プロセッサとして使う逆張りを選んでいます。
この設計思想を料理の手順で言い換えると、わかりやすくなります。NVIDIAのGPUクラスタは、巨大な仕込みを「複数の鍋で同時に煮込み、最後に大きな容器に集めて混ぜる」やり方です。一方Cerebrasは、最初からホールサイズの巨大鍋1つで全てを完結させる。鍋の間で具材を移し替える時間――つまりチップ間通信のレイテンシ――が原理的にゼロになります。
これにより、メモリ帯域は理論値で21PB/s(NVIDIA H100の約700倍)、チップ内コア数は90万コア規模に達します。LLM学習における通信ボトルネックを物理的に消し去る、ほぼ唯一の現実解として、OpenAIが大型発注に踏み切った技術的合理性は理解できます。
問題は、その合理性が意思決定者の個人的な経済利益と分離されていなかった点にあります。
【比較表】従来アーキテクチャとのスペック比較
| 項目 | NVIDIA H100 (GPUクラスタ) | NVIDIA B200 (Blackwell) | Cerebras WSE-3 |
|---|---|---|---|
| トランジスタ数 | 800億 | 2,080億 | 4兆 |
| オンチップメモリ | 80GB HBM3 | 192GB HBM3e | 44GB SRAM(オンダイ) |
| メモリ帯域 | 約3TB/s | 約8TB/s | 約21PB/s(=21,000TB/s) |
| コア数 | 約16,896 CUDAコア | 約20,000+ | 約90万コア |
| チップ間通信 | NVLink/InfiniBand必須 | NVLink 5世代 | 不要(単一ウェハー内完結) |
| 主要ユースケース | 汎用LLM学習・推論 | 次世代LLM学習 | 超大規模モデルの単一ジョブ学習 |
| 1チップあたりコスト目安 | 約3万ドル | 約4万ドル | 200万ドル超(システム単位) |
注目すべきは「メモリ帯域」と「チップ間通信」の項目です。GPUクラスタは外部接続の多段化で性能を稼ぐ構造、WSE-3はそもそも外部接続が不要という構造。設計哲学そのものが直交している点が、市場における代替可能性の議論を複雑にしています。
【図解】技術アーキテクチャ・関係図
【考察】ITエコシステム・業界へのインパクト
この訴訟が技術業界に与える衝撃は、判決の中身よりも「法廷で開示された資料」自体にあります。
第一に、NVIDIAの独占体制に対する圧力が現実化しました。Cerebrasへの1.5兆円発注という事実は、これまで「技術的には興味深いが商用調達は限定的」とされてきたウェハースケール製品が、トップティアのAI研究機関にとって実用フェーズに入ったことを意味します。
第二に、AI企業のガバナンス・コードが業界標準として形成される契機になり得ます。Brockman氏が承認した発注先の株式を個人保有していたという構図は、SaaSスタートアップではよくある話ですが、調達規模が国家予算級に達したAIラボでは話が別です。LP(※ファンドの出資者)やパートナー企業から、役員の保有銘柄リストの開示やリサイクル禁止条項を求める動きが、今後数四半期で顕在化するでしょう。
第三に、インフラ投資の地理的分散が加速します。CerebrasはUAE系のG42との連携を通じてアブダビにデータセンターを構築しており、米国の輸出規制とは別軸でAIコンピュートの供給網が育ちつつあります。OpenAIがNVIDIA一辺倒から脱却することは、AIインフラの「単一障害点リスク」を緩和する一方で、米国政府にとっては輸出管理の難易度を上げる要因になります。
そして実装エンジニアにとって最も重要なのは、学習ジョブのオーケストレーション設計が根本から変わる可能性です。GPUクラスタ前提のKubernetesスケジューリングや、Megatron/DeepSpeedのようなライブラリは「多数のチップを協調させる」発想で組まれていますが、ウェハースケール環境では「単一の超巨大プロセッサに最適配置する」発想に組み替える必要があります。MLOpsチームは今後、両方のスタックを並走させる覚悟を求められます。
まとめ
この裁判の本質は「AIが人類のためのものか、株主のためのものか」という哲学論争ではありません。AI半導体サプライチェーンの意思決定が、技術的合理性と経営者の個人収益のどちらに駆動されているかを、第三者が初めて検証できるようになったという、ガバナンス史上の転換点です。
WSE-3が技術的に優れていることと、その発注プロセスが利益相反まみれだったことは、両立します。エンジニアとして見るべきは、特定企業の株価や経営者の人物評ではなく、自社が依存するAIインフラの調達先がどのような意思決定プロセスを経て選ばれているかを、自分の言葉で説明できるかどうかです。
Cerebrasのチップは、これからより多くのAIラボのデータセンターに搬入されます。それは技術の必然です。しかし、その契約書の裏側で動いた金の流れまで、私たちは自分の選定基準に取り込めているでしょうか。
引用元記事・補足資料
- Live updates from Elon Musk and Sam Altman’s court battle over the future of OpenAI:The Verge記者による法廷ライブブログ。ブロックマン証言とCerebras株保有の質疑応答が時系列で記録されている一次的な現場報告。
- U.S. Securities and Exchange Commission (SEC) EDGAR:米国証券取引委員会の企業情報開示システム。Altman氏ら役員の個人財務開示書類の原本確認に利用可能。
- Superior Court of California, County of San Francisco:本訴訟が係属するサンフランシスコ高等裁判所のオンラインサービス窓口。ドメインが
sfsuperiorcourt.orgからsf.courts.ca.govへ移行済み。 - OpenAI Official Blog: OpenAI and Elon Musk:OpenAI側からの公式反論ポスト。提訴に対するOpenAI経営陣の主張と関連経緯を記載した公式声明。
- Cerebras Systems Press Releases:Cerebras社の公式プレスリリース一覧。WSE-3の仕様、Series H調達(評価額230億ドル)、IPO関連発表などを掲載。
- Bloomberg Technology:シリコンバレーAI巨大企業における利益相反疑惑の分析記事掲載元。
- The truth Elon left out — OpenAI:OpenAIが直近(裁判中)に公開した、Brockman氏の日記抜粋に対する公式反論記事。
- Cerebras Series H Financing — $23 Billion Valuation:記事中で言及した「評価額230億ドル」の数字を直接裏付けるBusinessWire配信プレスリリース。


コメント