
【エグゼクティブ・サマリー】
- GKEが「100万アクセラレータを単一制御プレーンで管理する」Hyperclusterを投入し、長年のクラスター分断問題を構造的に解決
- gVisorベースのGKE Agent SandboxがAIエージェント時代のセキュリティ基盤となり、サブ1秒起動と毎秒300サンドボックスを実現
- llm-dベースのPredictive Latency BoostによってTTFT(最初のトークン応答時間)を最大70%削減し、推論パスのボトルネックを解消
既存テクノロジーの限界と課題
AIエージェントが本番環境で動き始めた途端、インフラエンジニアは3つの根本的な壁にぶつかります。
第一の壁は「コンテナ隔離の限界」です。従来のDockerやrunc(※Open Container Initiativeに準拠した標準的なコンテナランタイム)は、ホストOSのカーネルを全コンテナで共有する設計になっています。
これは図書館の閲覧室で全員が同じ本棚を共有するようなもので、誰か一人が本棚に火をつければ全員が巻き添えになります。AIエージェントがLLMから生成した「未検証のコード」を実行する場面では、この共有モデルは致命的です。
第二の壁は「クラスター分断(Cluster Sprawl)」です。AIワークロードが拡大するにつれ、企業は数百の独立したKubernetesクラスターを抱えることになります。
- 学習用クラスター
- 推論用クラスター
- リージョンごとの本番クラスター
- 検証・サンドボックス用クラスター
これらが連携できず、リソース利用率が伸び悩むケースが多発しています。
第三の壁は「推論レイテンシの構造的な遅さ」です。HPA(※Horizontal Pod Autoscaler、Kubernetesの水平自動スケール機構)は外部の監視スタックからメトリクスを取得するため、反応に25秒前後を要します。
トークンを毎秒数百も吐き出すLLM推論にとって、25秒の遅延は永遠に等しい時間です。さらにKVキャッシュ(※Transformerが過去トークンの計算結果を保持するメモリ領域)はGPU/TPUのHBMを食い潰し、長コンテキスト処理のスループットを直接圧迫します。
ニュースの核心
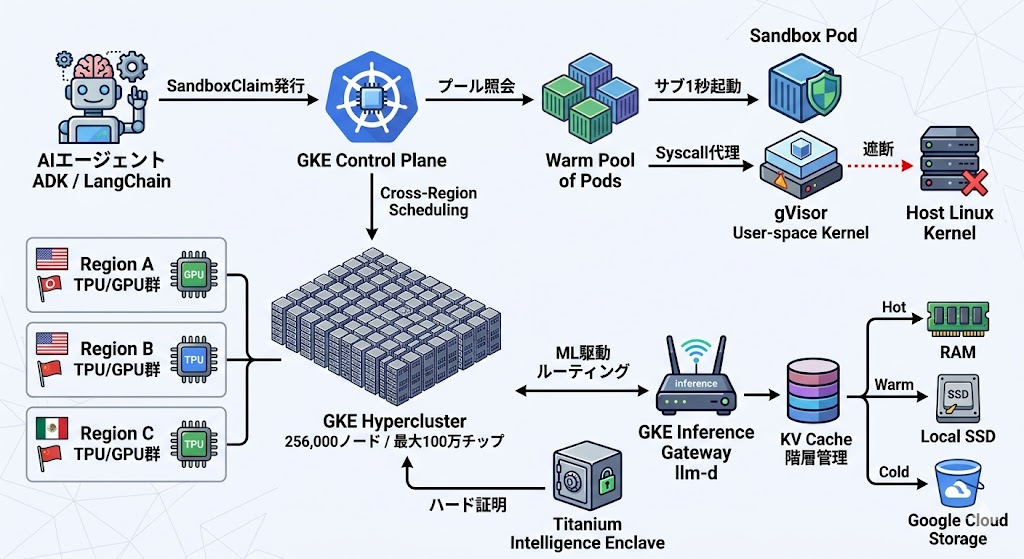
Googleが2026年5月にCloud Next ’26で発表した一連のGKE更新は、上記3つの壁を一気通貫で破壊する設計になっています。発表の中心は、GKE Agent SandboxとGKE Hyperclusterの2本柱です。
GKE Agent Sandbox:Geminiと同じ隔離技術をK8sプリミティブに昇華
GKE Agent Sandboxは、Geminiの本番環境を支えているのと同じgVisor(※Googleが開発したユーザー空間で動作するミニカーネル)を、Kubernetes標準のリソースとして公開する仕組みです。
GKE Agent Sandbox provides kernel-level isolation for untrusted agent code execution using gVisor, the same sandboxing technology that secures Gemini. Google claims 300 sandboxes per second at sub-second latency and up to 30% better price-performance when running on Axion compared to other hyperscale clouds.(出典:InfoQ/Google Cloud公式発表)
このサンドボックスはレストランの厨房に隣接する独立した試食室として動作します。試食室で何が爆発しようと、本厨房の調理ラインは止まりません。技術的には、ゲストOSのシステムコールをホストカーネルではなくgVisor(ユーザーランドで動くプロキシカーネル)が代理で受け取るため、コンテナ内の暴走コードはホストカーネルに到達できないわけです。
注目すべきは、Agent Sandboxが3つの新しいKubernetesプリミティブ(※K8sの基本リソースタイプのこと)として実装されている点です。
- Sandbox:ワークロード本体を表すリソース
- SandboxTemplate:セキュリティポリシーの設計図
- SandboxClaim:ADKやLangChainなど高レベルフレームワークから実行環境を要求するためのトランザクショナルリソース
つまりエージェントフレームワーク側は「サンドボックスが欲しい」と宣言するだけで、Kubernetes側がプール化された温かいPodから即座に環境を払い出します。コールドスタート問題が1秒未満で解消されているのは、このウォームプール設計によるものです。
Lovable, whose platform supports 200,000+ new AI-generated projects daily, is running production workloads on Agent Sandbox.(出典:InfoQ)
LovableのCEOは、毎秒数百のセキュアサンドボックスへスケールできる点を本番運用の決め手として挙げています。
競合状況を整理すると以下のようになります。
- Cloudflare:コンテナベースのSandboxes GA、加えてV8 isolateベースのDynamic Workers
- E2B:Firecracker microVMによるVM級隔離
- Google GKE:gVisorによるユーザー空間カーネル隔離
3大ハイパースケーラーの中でネイティブのエージェントサンドボックスを提供しているのは現時点でGoogleのみであり、しかもKubernetes SIG Appsのサブプロジェクトとしてオープンソース化されています。
GKE Hypercluster:100万チップを単一制御プレーンで束ねる
もう一方の主役、Hyperclusterはスケールの方向に振り切った設計です。
A single, conformant GKE control plane manages a million chips distributed across 256,000 nodes spanning multiple regions. Security relies on Google’s Titanium Intelligence Enclave, a hardware-attested, “no-admin-access” model where proprietary model weights and prompts remain cryptographically sealed from platform administrators.(出典:InfoQ)
100万チップを1つの制御プレーンで管理するというのは、東京・大阪・福岡の物流センター全体を、東京の管制室1つから棚の在庫1個単位で指示するようなものです。実装としては、複数リージョンに分散したノード群を論理的に単一のクラスターとして見せかけ、スケジューラーが地理を越えてリソースを配置します。
ただし、Google Cloud AmbassadorのAlex Gkiouros氏は、この構想に対する現実的な懸念も指摘しています。
A single GKE control plane managing a million chips across regions sounds wonderful until you think through blast radius and change management. Private GA is the right place for it.(出典:InfoQ)
制御プレーンが単一であるということは、その制御プレーンが落ちた瞬間に100万チップ全体への指示系統が止まるリスクを内包しています。Private GA(※限定提供版)でクローズドにスタートする判断は、この技術的成熟度を反映しているわけです。
セキュリティ面では、Titanium Intelligence Enclaveがハードウェア証明(※CPUレベルで実行環境の完全性を暗号的に保証する仕組み)を用いて、Googleのプラットフォーム管理者でさえテナントのモデル重みを覗けない構造を実現しています。
推論レイヤーの最適化:Predictive Latency BoostとKVキャッシュ階層化
加えて、推論パスにも構造的なメスが入りました。
Predictive Latency Boostは、CNCF Sandboxプロジェクトとなったllm-d(※LLM推論に特化した分散ルーティングプロジェクト)を基盤とし、機械学習駆動のルーティングでTTFT(※Time-to-First-Token、最初のトークンが返ってくるまでの時間)を最大70%削減します。
ヒューリスティックな勘でリクエストを振り分けるのではなく、各Podの実時間容量を見ながら配分する仕組みです。
KVキャッシュの自動階層化も注目に値します。アクセス頻度に応じてデータを振り分ける挙動は、図書館員が今週貸し出しの多い本を貸出カウンターの真横に、年に1回しか借りられない本を地下書庫の奥に置く運用と同じ発想です。
- 短期:RAM
- 中期:Local SSD
- 長期:Google Cloud Storage
Googleの計測では、10Kトークンのプロンプトをオフロードした場合のスループットが50%向上、50Kトークンでは70%近い改善が報告されています。長コンテキスト処理におけるメモリ壁問題を、ストレージ階層化で逃がす戦略です。
そしてHPAの遅さに対しては、インテントベース・オートスケーリングが答えを用意しています。外部監視スタックを経由せず、Pod自身が直接メトリクスを発信することで、25秒だった反応時間を5秒に短縮しています。
【比較表】従来アーキテクチャとのスペック比較
| 項目 | 従来GKE / 標準Kubernetes | GKE Hypercluster + Agent Sandbox |
|---|---|---|
| 単一制御プレーン管理可能チップ数 | 数千〜数万 | 最大100万チップ/256,000ノード |
| 隔離方式 | runc(カーネル共有) | gVisor(ユーザー空間カーネル) |
| サンドボックス起動レイテンシ | コールドスタート数秒〜数十秒 | サブ1秒(ウォームプール) |
| サンドボックス並列起動 | 仕様外 | 毎秒300サンドボックス |
| 推論TTFT | ヒューリスティックルーティング | ML駆動ルーティングで最大70%削減 |
| HPA反応時間 | 約25秒 | 約5秒(インテントベース) |
| KVキャッシュ階層化 | アプリ実装依存 | RAM/SSD/GCSの自動階層化 |
| モデル重みの保護 | RBAC依存 | Titanium Intelligence Enclaveによるハード証明 |
| 主要ユースケース | 一般Webワークロード、CI/CD | フロンティアモデル学習、AIエージェント実行 |
【図解】技術アーキテクチャ・関係図
【考察】ITエコシステム・業界へのインパクト
今回の発表が業界構造に与える影響は、3つのレイヤーで現れると考えられます。
第一に、Kubernetesの位置付けの転換です。 これまでKubernetesは「コンテナオーケストレーター」と定義されてきましたが、Agent Sandboxの導入により「AIエージェントランタイム」という新しいポジションを取りに行ったと読み取れます。
gVisorをKubernetes SIGのサブプロジェクトとしてオープンソース化していることが象徴的で、Googleは「自社GKEの差別化機能」ではなく「Kubernetes標準」として定着させる戦略を選びました。Cloudflareの独自エッジサンドボックスやE2BのmicroVMアプローチに対し、標準化の力で勝負するという意思表示です。
第二に、ハイパースケーラー間の垂直統合競争の激化です。 Googleはシリコン(TPU)からネットワーク、Kubernetes、推論ゲートウェイまでを一貫して内製化しています。
NVIDIAがVera Rubin PODでラック規模の統合を進める一方、Googleは「100万チップ単一制御プレーン」というスケール軸で対抗するわけです。AWSのTrainium/Inferentia、Microsoftのカスタムシリコンも含め、AIインフラ市場は水平分業から垂直統合への揺り戻しフェーズに入ったといえます。
第三に、運用エンジニアのスキルセットの変質です。 Sandbox、SandboxTemplate、SandboxClaimといった新プリミティブは、従来のPod/Deployment/Serviceに次ぐ第二世代の抽象化です。
AIエージェントの安全な実行管理が、SREやプラットフォームエンジニアの主戦場になります。具体的には以下のスキルが価値を増します。
- gVisor/カーネル隔離技術の運用知識
- KVキャッシュとストレージ階層の最適配置設計
- 大規模分散制御プレーンのBlast Radius(※障害が波及する範囲)管理
- llm-dベースの推論ゲートウェイ運用
逆に、単純なrunc前提のコンテナ運用知識は陳腐化の方向に進むと予想されます。
まとめ
Googleが今回提示したのは、AIワークロードに「Kubernetesを使う」のではなく、Kubernetes自体をAIエージェント実行基盤に作り変えるという構造変化です。
100万チップ単一制御プレーンというスケールは、運用上のBlast Radiusという別のリスクを生むため、Private GAでの慎重なロールアウトは賢明な判断です。一方で、gVisorのオープンソース戦略は、ハイパースケーラーの差別化機能を業界標準に押し上げる動きであり、長期的にはNVIDIA中心のクローズドエコシステムに対する効果的な対抗軸になり得ます。
エンジニアが今すぐ取るべき行動は明確です。SandboxClaimプリミティブの仕様に目を通し、自社のエージェント基盤がgVisor隔離前提で設計されているかを点検すること。Firecrackerやrunc前提のアーキテクチャは、3年以内に大きな見直しを迫られます。
引用元記事・補足資料
- Google Announces GKE Agent Sandbox and Hypercluster at Next ’26, Positioning Kubernetes as AI Agent:本記事のベースとなったInfoQによる発表速報。Hypercluster/Agent Sandboxの主要数値と業界コメントを網羅。
- Google Cloud Blog: Announcing Google Kubernetes Engine updates at Cloud Next ’26:Google Cloud公式による一次発表ブログ。GKEアップデート全体像の出典。
- About GKE Agent Sandbox(Google Cloud公式ドキュメント):Agent Sandboxのカーネルレベル隔離・サブ秒プロビジョニング・CRD設計を解説した一次仕様。
- GitHub – google/gvisor:GKE Agent Sandboxの基盤となるgVisorのオープンソースリポジトリ。
- Google Cloud Research: Accelerating AI agents with TPU generations:次世代TPUの技術的背景となるTPU v5p公式ドキュメント。
- CNCF Annual Survey 2025: Kubernetes Established as the De Facto ‘Operating System’ for AI:本番Kubernetes採用率82%、AI推論ワークロードの66%がK8s上で稼働しているという数値の一次出典。
- TPU v6e vs GPU: 4x Better AI Performance Per Dollar(Introl分析レポート):TPUとNVIDIA H100のTCO(総保有コスト)を比較し、Snapが55%のコスト削減を実現した事例などを含む実証データ。

コメント