
【エグゼクティブ・サマリー】
- AIチップの進化でトークン単価は下がり続けているのに、エージェントAIは1つの指示をこなすのに最大1000倍のトークンを消費するため、企業のAI総コストが人件費を逆転し始めた。
- 真犯人は「コンテキストの雪だるま化」という構造問題。エージェントは一手進むたびに過去の全履歴を読み直すため、作業ステップ数が増えるほどコストが指数関数的に膨張する。
- MicrosoftはClaude CodeをGitHub Copilot CLIへ切り替え、AmazonやMetaは社内利用を制限。市場の評価軸は「モデルの賢さ」から「推論コスト効率」へと急速に移りつつある。
既存テクノロジーの限界と課題
今回のニュースを理解するには、まず現在のAIの料金体系とアーキテクチャ(※システムの基本構造のこと)が、そもそも自律型AIを想定して作られていないという前提を押さえる必要があります。
ここには、大きく3つの構造的なボトルネックが潜んでいます。
- ① 定額制(フラットレート)の崩壊:月額サブスクは「人間が手でポチポチ入力する速度」を前提に価格設計されています。ところが自律型エージェントは1日に数千回ものAPI(※ソフト同士がやり取りする窓口のこと)呼び出しを自動で回すため、人間用の前提が根本から崩れます。
- ② トランスフォーマーの計算量の壁:現在のLLM(※大規模言語モデルのこと)の心臓部であるアテンション機構(※文章中のどの単語が重要かを判断する仕組み)は、入力する文章が長くなるほど計算量が爆発的に増えます。文章が2倍になれば、計算負荷はおおむね4倍に膨らむ性質を持っています。
- ③ AIは「記憶喪失」である:LLMは会話の状態を内部に保存しません。会話を続けているように見えても、その実態は毎回、過去のやり取り全文をまるごと読み直して、初めて返事をしているだけなのです。
食べ放題のビュッフェを思い浮かべてください。普通の客が来る前提で「90分2,980円」という値付けをしていた店に、24時間ノンストップで食べ続ける大食いロボットが100体押し寄せたら、その店は一瞬で潰れます。
いま定額制のAIサービスで起きているのは、まさにこの構図です。実際にAnthropicは、サブスク利用者が自律エージェントを回すことを制限しました。フラット料金のサブスクは人間の速度のやり取り向けに設計されており、自律エージェントが1日に数千回のAPI呼び出しを行う負荷は経済的に持続不可能だと判断したためです。
ニュースの核心
米Tom’s Hardwareが報じた今回の騒動の本質は、「トークン単価が下がっているのに、総額はむしろ膨れ上がっている」という逆説にあります。
その金額感を一発で突きつけたのが、人気の自律コーディングツールOpenClawを開発したPeter Steinberger氏のケースです。わずか3人のチームが約100個のCodexインスタンスを走らせ、30日間で603億トークン・760万リクエストを消費し、請求額は130万ドル(約1,305,088ドル)に達しました。
なぜ、たった数人のチームがこれほどのトークンを溶かせるのか。鍵は「コンテキスト(※AIに渡す文脈・履歴情報のこと)の雪だるま化」にあります。
会議の議事録を思い浮かべてください。発言するたびに、議長が「では、ここまでの議事録を最初から全部読み上げます」と全文を朗読してから次の発言に移る——そんな会議があったら、終盤の一言を発するためだけに膨大な時間と紙が消費されるはずです。
エージェントAIの内部では、これと全く同じことが起きています。スタンフォード大学デジタル経済研究所の分析は、この仕組みを的確に説明しています。
高コストの正体は出力トークンではなく入力トークンにある。エージェントはタスクを読み、応答を得たあと、次の行動の前にすべて(元の指示と応答)を読み直す。さらに次の行動の前に、それら全部に加えて新しい応答も読み直す——大きく高価なコンテキストの雪玉を転がしていくのだ
つまり、1ステップごとに「過去の全文+新しい結果」を再投入し、それに毎回課金される。この再読み込みが積み重なるため、エージェントのタスクはコード推論やチャットの1000倍ものトークンを消費するという、際立って高コストなものになるわけです。
そしてもう一つの問題が、人間側の振る舞いです。AI利用が社内評価の指標になった結果、「トークンマックス(tokenmaxxing)」——とにかくトークンを使うこと自体が目的化する現象——が蔓延しました。
歩数計の数字を稼ぐためにスマホをただ振り続けるように、本来は不要な作業にまでAIを使い、社内ダッシュボードの数字を盛る動きが各社で観測されています。NVIDIAのジェンスン・フアンCEOは、年収50万ドルのエンジニアが少なくとも25万ドル分のトークンを消費していなければ「深く憂慮する」と述べ、1人あたりのトークン消費量を重要指標として強調しました。
この圧力の行き着いた先が、企業の方針転換です。The VergeのTom Warren氏の報道によれば、Microsoftは社内のClaude Codeライセンスの大半を解約し、エンジニアを2026年6月30日までにGitHub Copilot CLI(※ターミナル上で動くコーディング支援ツールのこと)へ移行させる方針を打ち出しました。社内で最も人気だったツールを、コストと戦略の都合で手放すという、象徴的な”プルバック(後退)”です。
【比較表】従来アーキテクチャとのスペック比較
| 項目 | 従来型AI(単発のLLM問い合わせ) | エージェントAI(自律型) |
|---|---|---|
| トークン消費量(目安) | 1リクエスト分のみ | 最大1000倍(ステップ数に比例して増大) |
| 処理の流れ | 質問 → 推論 → 1回で回答 | 読込 → 行動 → 全履歴を再読込 → 行動…の反復 |
| レイテンシ(応答速度) | 数秒で完結 | 数分〜数十分(多段階処理のため) |
| 必要な計算リソース | 単発・予測可能 | 多重・予測困難(GPUを長時間占有) |
| コスト構造 | リクエスト単位で見積もり可能 | コンテキスト肥大により指数的に膨張 |
| 主なユースケース | チャット、要約、翻訳、Q&A | コード自動修正、PRレビュー、複数ステップの業務自動化 |
【図解】技術アーキテクチャ・関係図
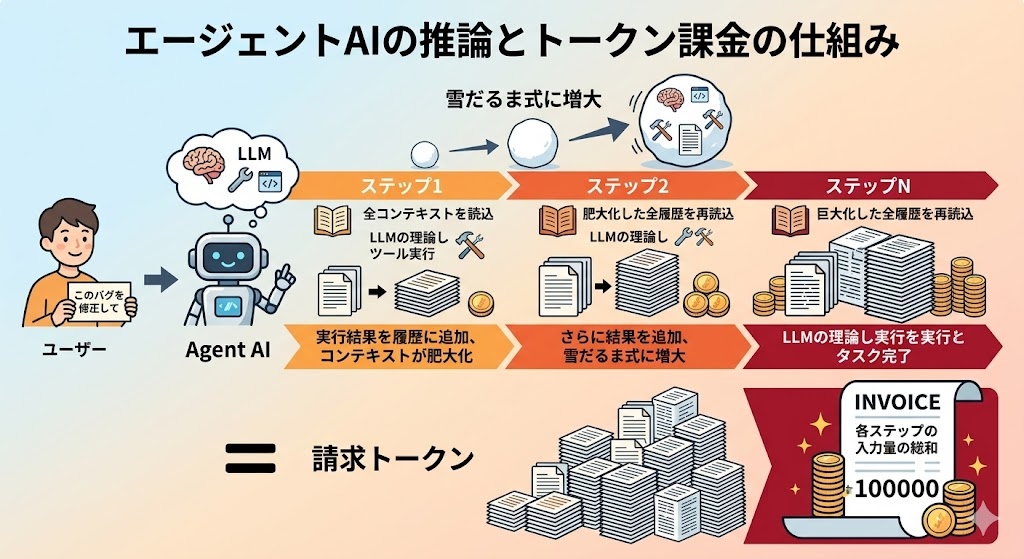
色が濃くなる丸い箱(再読込のステップ)に注目してください。処理が進むほど読み直す量が増え、その入力すべてに課金される——これがコスト爆発のメカニズムを一枚で表しています。
【考察】ITエコシステム・業界へのインパクト
この現象の経済学的な背骨にあるのが「ジェボンズのパラドックス」です。技術が効率化して単価が下がると、消費総量がかえって増えてしまうという法則を指します。
高速道路の車線を増やすと渋滞が解消されるどころか、「空いているなら乗ろう」という車が誘発されて、結局また渋滞する——あの現象とまったく同じ力学が、いまトークン市場で働いています。トークンが安くなったからこそ、人々は1000倍使うようになったのです。
ここから読み取れる業界へのインパクトは、立場によって正反対の意味を持ちます。
- 短期(クラウド・GPU需要):トークン消費の爆発は、推論インフラへの需要をむしろ押し上げます。GPUを売る側、データセンターを貸す側にとっては追い風が続きます。
- 中長期(CAPEXの逆風):企業がコスト削減のためにAI利用を絞り始めれば、ハイパースケーラーの設備投資(※CAPEX=事業のための大型先行投資のこと)の伸びが鈍化し、AIインフラ関連銘柄の成長シナリオに見直しが入るリスクがあります。
- 競争軸のシフト:勝負どころは「賢さの自慢」から「同じ仕事をいかに少ないトークンで終わらせるか」という推論コスト効率へ移ります。コンテキストの圧縮、キャッシュの再利用、無駄なステップの削減といった”地味な最適化”が、そのまま競争力に直結します。
技術者にとって重要なのは、ここでの本当の指標はトークン消費量ではなくROI(※投資対効果のこと)だという一点です。10億トークンを燃やして誰もレビューしない大量のコードを吐くエンジニアより、1億トークンで実際に出荷まで漕ぎ着けるエンジニアの方が、当然ながら価値が高い。ダッシュボードの数字は、生産性の代理指標としては壊れているのです。
まとめ
トークン単価は今後も下がります。しかし、1つのタスクを終えるのに必要なトークン数が、単価が下がる速度を上回って増え続けるなら、計算式の答えはマイナスになります。
CFO(最高財務責任者)が「コンピュートのコストが人間1人分に並ぶなら、人間を減らしてコンピュートを増やせばいい」と問うた瞬間、トークンマックス文化は皮肉にも自らの首を絞めます。各人にひもづいたコンピュート単価を、目に見えるほど大きく可視化してしまったからです。
問われているのは、AIをどれだけ使ったかではなく、そのトークンが本当に成果へ変換されたか。雪だるまを大きくする競争から降り、雪玉を小さく転がす技術を持つ者が、次のフェーズの主導権を握ります。
引用元記事・補足資料
- AI cost crisis hits tech giants as employee ‘tokenmaxxing’ backfires (Tom’s Hardware):本記事の主軸。トークンマックスとコスト逆転現象を報じた一次報道。
- OpenClaw creator burns through $1.3 million in OpenAI API tokens in a single month (Tom’s Hardware):30日で603億トークン・130万ドルという具体的なコストデータの出典。
- How are AI agents spending your tokens? (Stanford Digital Economy Lab):エージェントが1000倍のトークンを消費する技術的理由(入力側の雪だるま化)を分析した学術ソース。
- Stop ‘tokenmaxxing’ and deploy AI sensibly instead (Nature Machine Intelligence):トークンマックス現象の妥当性と弊害を論じた専門誌の論考。
- The Verge / Tom Warren:”Microsoft starts canceling Claude Code licenses”(Notepadニュースレター, 2026-05-14):MicrosoftがClaude CodeからCopilot CLIへ移行する方針を最初に報じた一次ソース。
- Big Tech has a tokenmaxxing habit (Tom’s Hardware):Meta・Amazonの社内リーダーボードやジェンスン・フアン発言など、補足背景の出典。
- IATA – Industry Statistics & Forecasts:航空需要が2050年に倍増する見通し(ジェボンズのパラドックスの歴史的事例)の参照元。


コメント