
【エグゼクティブ・サマリー】
- Armが従来のIPライセンス事業から脱却し、自社設計・販売のデータセンター向け「Arm AGI CPU」を正式に発表。
- 136基のNeoverse V3コア、12ch DDR5-8800、CXL対応を誇り、次世代のエージェント型AIワークロードに最適化。
- サーバー向けCPU市場においてAMDやIntel、NVIDIAと直接競合することになり、半導体エコシステムを根本から再編する歴史的転換点に。
既存テクノロジーの限界と課題
新たなアーキテクチャの優位性を語る前に、なぜ今データセンター向けCPUにパラダイムシフトが求められているのか、その「物理的・構造的なボトルネック」を整理します。
最大の課題は、AIインフラにおける「メモリの壁(Memory Wall)」と「電力密度の限界」です。現在、自律的に思考・行動する「エージェント型AI」の普及が進んでいますが、このワークロードは従来のバッチ処理や単一の推論タスクとは性質が異なります。複数のAIモデルや外部ツール間の高度なオーケストレーションを低遅延で実行するためには、プロセッサコアの数だけでなく、「各コアにいかに高速にデータを供給できるか」というメモリ帯域幅が決定的な制約となります。
既存のx86アーキテクチャ(特に空冷環境下の高TDPモデル)では、コア数を増やすほどコアあたりのメモリ帯域幅が犠牲になりやすく、また消費電力の肥大化によって1ラックあたりの搭載密度(一般的に空冷で約36kW上限)が頭打ちになっていました。DRAMの供給不足と高騰も相まって、これまでの「力技」によるインフラ拡張は、物理的にもコスト的にも限界に達しつつあったのです。
ニュースの核心とアーキテクチャの優位性
こうした課題に対する明確な解答として発表されたのが、今回の「Arm AGI CPU」です。米テクノロジーメディアServeTheHomeの報道によると、Armは従来のIP(知的財産)ライセンス提供というビジネスモデルの枠を超え、ついに完全な物理チップ(シリコン)の販売に乗り出しました。
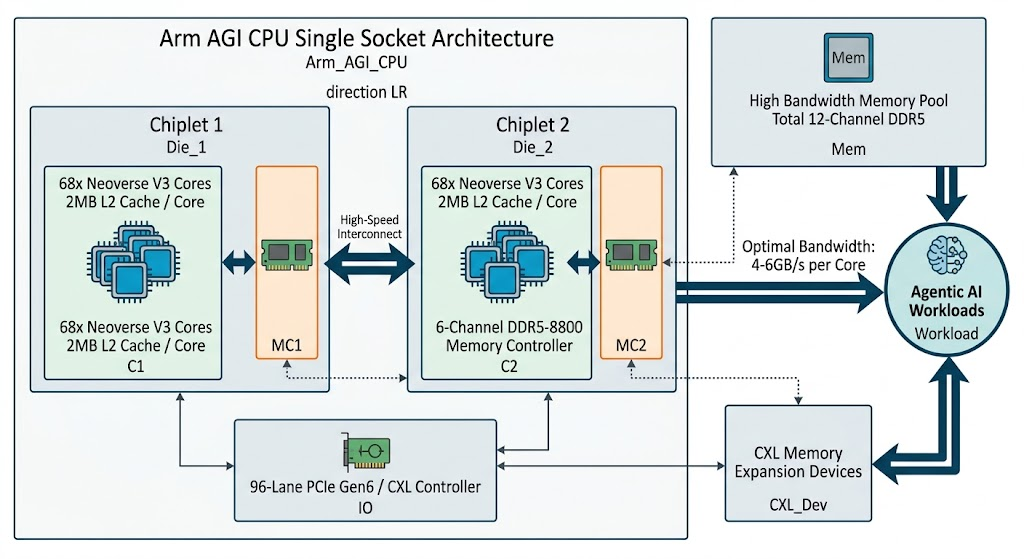
アーキテクチャの観点から見たこのプロセッサの驚異的な仕様は、以下の要素に集約されます。
“The new design will bring up to 136 Arm Neoverse V3 cores into a single socket.” (意訳:この新しい設計は、シングルソケットに最大136基のArm Neoverse V3コアをもたらす。)
Microsoft Azureのカスタムチップ「Cobalt 100(132コア)」をわずかに上回るこの集積度は、TSMCの先端プロセス(推測される3nm世代)の恩恵によるものです。さらに特筆すべきは、その足回りの堅牢さです。
- デュアルチップレット設計: Intelの第5世代Xeon(Emerald Rapids)に似たアプローチを採用。2つのダイにPCIeとメモリコントローラを分散・統合させることで、歩留まりの向上とI/O性能の最適化を両立しています。
- 12チャネル DDR5-8800と大容量キャッシュ: 各コアに2MBのL2キャッシュを搭載。さらに、高速なDDR5メモリを12チャネルで並列アクセス可能にしています。
- PCIe Gen6およびCXLサポート: 96レーンのPCIe Gen6を搭載し、CXL(Compute Express Link)メモリ拡張モジュールに標準対応。これにより、高価なメインメモリに依存せずとも、大容量・広帯域なメモリプールを柔軟に構築できます。
“Arm says that 4-6GB/s is the sweet spot for per core memory bandwidth.” (意訳:Armは、コアあたりのメモリ帯域幅のスイートスポットは4〜6GB/sであると述べている。)
この「コアあたり4〜6GB/s」という指標こそが、エージェント型AIのワークロードを遅延なく処理するための最適解であり、Armが他社ソリューションに対して優位性を主張する最大の根拠となっています。
【図解】技術アーキテクチャ・関係図
今回のArm AGI CPUのアーキテクチャ構造と、それがエージェント型AIワークロードにどう作用するのかを図解します。
【エンジニア視点】ITエコシステム・業界へのインパクト
このニュースの真のインパクトは「Armのチップが速い」ということ以上に、「データセンターと半導体業界の垂直統合モデルの再編」にあります。
これまで、AWSのGravitonやGoogleのAxion、MicrosoftのCobaltなど、巨大クラウドベンダー(ハイパースケーラー)はArmのIPをライセンスし、自社のデータセンターに最適化した「カスタムシリコン」を内製化してきました。しかし、今回Arm自身が「完成品としての高性能プロセッサ(Off-the-shelf silicon)」を提供し始めることで、自社でチップを開発するリソースを持たない中規模のクラウド事業者やエンタープライズ企業(SAPやCloudflareなどが顧客として言及されています)でも、ハイパースケーラーと同等かそれ以上のAIインフラ制御基盤を即座に手に入れられるようになります。
また、インフラ設計の観点では「集積密度」の劇的な向上が見込まれます。記事によれば、ORv3(Open Rack v3)仕様の36kW空冷ラックに8,000コア以上を詰め込むことが可能になり、水冷環境であれば100kW級の超高密度ラックが現実のものとなります。GPUが重い計算処理(学習・推論)を担い、このArm AGI CPUがデータ移動やエージェントの自律的オーケストレーションを担う、という次世代の役割分担が明確になるでしょう。
競合他社への影響も甚大です。記事内でArmが比較対象としてIntel XeonではなくAMD EPYCを挙げている点は非常に示唆に富んでいます。AI制御ノードの市場において、ArmはAMDを直接的な脅威、あるいは追い落とす対象として認識しています。さらに、NVIDIAのGrace CPUとも直接競合するため、AIインフラにおける「覇権争い」の構図はさらに複雑化するはずです。
まとめ
Armの「Arm AGI CPU」投入は、単なる新製品の発表ではなく、同社がシリコンプロバイダーへと変貌を遂げる歴史的マイルストーンです。136基のNeoverse V3コアと徹底的な広帯域メモリ設計により、エージェント型AIのワークロードにおける従来のボトルネックを打破する可能性を秘めています。
2026年後半の量産化に向け、LenovoやSupermicroなどのOEMパートナーも既にシステム開発に動いています。今後、データセンターのサーバー選定において、x86とArmの勢力図がどのように変化するのか、我々インフラエンジニアはアーキテクチャの根幹から知識をアップデートし続ける必要がありそうです。

コメント